이번 포스팅에서는 Transformer을 이어서 살펴보도록 하겠습니다.
Transfromer를 이해하기 위해선 6개의 모듈을 이해해야 됩니다. (Input Layer, Positional Encoding, Multi-Head Attention, Masked Multi-Head Attention, Add. & Norm. Layer, Feed Forward Layer) 이전 포스팅에서는 Input Layer, Positional Encoding을 살펴보았고, 이번 포스팅에서는 나머지 모듈을 살펴보려고 합니다.
Transformer

Self-Attention?
Input에 Positional Encoding을 더해준 후 Attention Layer에 진입하게 됩니다. 예전 포스팅에서 언급된 것 처럼 Attention은 Query, Key, Value에 대한 함수로 이해할 수 있습니다. Self-attention이란 Query, Key, Value가 같은 것을 참조하는 Attention Mechanism을 말합니다. 직관적으로 이해하기 위해, "Do not touch the pot because it is very hot" 이라는 문장을 생각해보겠습니다. 번역 이전에 대상 문장을 잘 이해할 필요가 있습니다. 문장에 'it'이 등장하는데 이는 대상문장 자체에 있는 "pot"을 대신합니다. Self-attention을 적용하면 입력문장을 더 잘 이해할 수 있게 됩니다. Transformer에는 self-attention이 입력값을 받은 직후에 적용되며, Encoder의 Multi-Head Attention과 Decoder의 Masked Multi-Head Attetion이 이에 해당합니다. 우선은 Self-attention은 Q, K, V가 같은 것을 참조하는 방법이라는 것을 이해하고, Encoder, Decoder순으로 내부의 각 모듈을 구체적으로 살펴보겟습니다.
Encoder & Decoder
Input에 Positional Encoding이 더해지고 나면, Encoder, Decoder를 통과하게 됩니다. Encoder와 Decoder는 몇 가지 모듈로 구성되어 있으며, Fig.1에서 보다시피 $N$ stacks을 합니다. "Attention is all you need"에서는 Encoder와 Decoder 모두 6개 층을 적재한 형태를 적용했습니다.
Encoder는 Multi-Head Attention, Add&Norm., Feed Forward Layer로 구성되어 있습니다. 먼저 Embedding vector를 Multi-Head Attention 함수에 통과시켜 결과 값(1-1)을 얻고, Embedding Vector와 Attention 함수의 결과 값을 Add&Norm. Layer에 통과시키며, 이는 Residual Connections이라고 부릅니다. 지금까지의 결과(1)을 Feed Forward에 통과 시켜 결과(2-1)를 얻고, 마찬가지로 결과(1)과 결과(2-1)을 Add&Norm. Layer에 통과시키는 모듈로 구성되어 있습니다.
Decoder는 Masked Multi-Head Attention, Add&Norm, Multi-Head Attention, Feed Forward Layer로 구성되어 있습니다. 첫 단추는 Encoder 처럼 Embedding vector를 Masked Multi-Head Attention 함수에 통과시켜 결과 값(1-1)을 얻고, Embedding Vector와 Attention 함수의 결과 값을 Add&Norm. Layer에 통과시킵니다. (Masked가 붙은 이유는 뒤에서 자세히 살펴보겠습니다.) Encoder와 다르게 Decoder에서는 Attention 모듈이 한 번 더 있는데, Query는 Decoder의 Masked Multi-Head Attetion의 Residual Connection 결과를, Key와 Value는 Encoder의 결과 값을 참조한 Multi-Head Attetion을 진행하고 마찬가지로 Residual Connection을 해줍니다. 마지막은 Encoder와 동일하게 Feed Forward Layer에 통과시키고, Residual Connection을 해주도록 구성되어 있습니다.
Multi-Head Attention
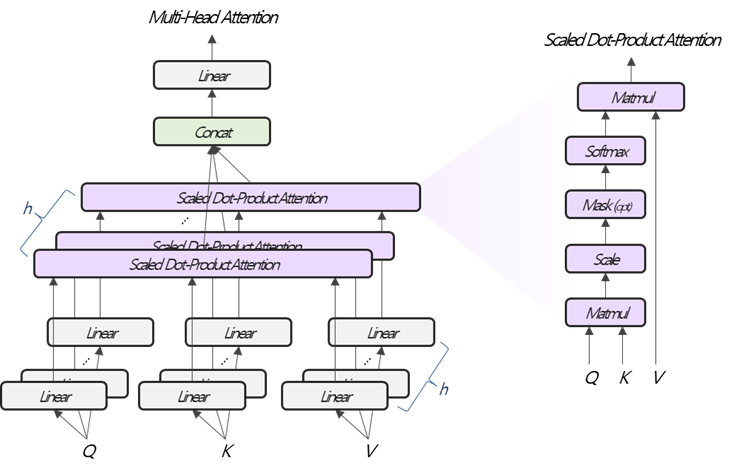
Multi-Head Attention은 Query, Key, Value를 입력받는 함수입니다. Encoder에서 한 번, Decoder에서 두 번 적용되는데, 입력 값의 차이가 존재하고, Scaled Dot-Product Attention 내부의 Masking 부분을 진행하고 말고의 차이가 있을 뿐 본질적으론 같습니다.
| Query | Key | Value | Masking | ||
| Encoder | Multi-Head Attention | Input Emb. | Input Emb. | Input Emb. | x |
| Decoder | Masked Multi-Head Attention | Output Emb. | Output Emb. | Output Emb. | o |
| Decoder | Multi-Head Attention | Decoder Out. | Decoder Out. | Encoder Out. | x |
Multi-Head Attention은 크게 Multi-Head와 Attention을 나누어서 생각할 수 있습니다. Multi-Head는 분산처리와 Embedding 값을 다방면으로 살펴보는데 목적이 있고, Attention의 경우 상황에 따라 집중해서 살펴볼 곳을 다르게 하는데 목적이 있습니다. Multi-Head와 Attention을 결합함으로써 빠르고, 그리고 기능별로 다양하게 집중해서 볼 곳을 찾을 수 있게 됩니다. Fig. 2를 기준으로 Gray Block, Purple Block, Green Block, Yellow Block을 순서대로 살펴보겠습니다.
Gray Block
Multi-Head은 Q, K, V에 대응하는 Embedding 값에 가중치 행렬을 곱하여 논리적으로 쪼개어 주는데 있습니다. 즉, $W_{Q}^{(i)}\in\mathbb{R}^{d_{model}\times d_{k}}$, $W_{K}^{(i)}\in\mathbb{R}^{d_{model}\times d_{k}}$, $W_{V}^{(i)}\in\mathbb{R}^{d_{model}\times d_{v}}$를 각각 Q, K, V에 곱하여 쪼개어 줍니다. Q, K, V는 어떤 Embedding값을 참조하는지에 따라서 row dimension은 바뀔수 있어 $\cdot \times d_{model}$크기를 갖고, $QW_{Q}^{(i)}$, $KW_{K}^{(i)}$,$VW_{V}^{(i)}$ , Fig.2 에서 첫 Linear 연산을 마치면, $\cdot\times d_{k}$, $\cdot\times d_{k}$, $\cdot\times d_{v}$의 크기로 나뉘게 됩니다.
Purple Block
Attention은 Luong Attention인 Dot-Product Attention에서 Scaling해주는 것이 추가된, Scaled Dot-Product Attention을 적용합니다. 이때 Scaling은 Q, K의 Embedding Vector 크기의 Squared Root 값인 $\sqrt{d_{k}}$로 해줍니다. 단순히 Linear 함수가 통과되어 논리적으로 쪼개진 Q, K, V를 입력받는다는 차이만 존재합니다. 이를 수식으로 요약해보면, $$Attention(QW_{Q}^{(i)}, KW_{K}^{(i)}, VW_{V}^{(i)})=Softmax\left[\frac{QW_{Q}^{(i)}\left(KW_{K}^{(i)}\right)^{\top}}{\sqrt{d_{k}}}\right]VW_{V}^{(i)}$$ 결국 $\cdot \times d_{v}$의 크기를 갖는 Attention Value를 출력합니다. 이때 $d_{v}$는 임의로 정하면 되고, 논문에서는 $d_{model}=512$, $h=8$로 $d_{v}=64$로 정의했습니다.
Fig. 2의 Scaled Dot-Product Attention에 보면, Optional한 Masking 부분이 있습니다. Masking은 Self-Attention을 할 때, 미리 정답지를 보지 않기 위하여, 문장 순서상 뒤에 위치하는 토큰을 못보게 만들어주는 장치입니다. 특히 Decoder에 적용되었는데, 그도 그럴 것이 Teacher Forcing 방식으로 학습을 시키기 때문입니다. Masking을 하는 방법은 아주 작은 숫자를 더해주는 것 입니다. 이는 Softmax 함수가 아주 작은 값에서 0되는 특성을 이용하는 것 입니다. 즉, $QW_{Q}^{(i)}\left(KW_{K}^{(i)}\right)^{\top}$ 결과에서 뒷 순번에 아주 작은 값(예를 들면,-99999999)을 더 해 줍니다. 예를 들어, 1 2 3 4라는 문장의 Embedding을 Q, K로 받고 Masking을 한다면 아래 Fig. 3처럼 처리할 수 있습니다.

Green Block
Scaled Dot-Product Attention을 지나고 나면, $h\times\cdot \times d_{v}$의 중간 출력 값을 얻습니다. Concat에서는 이를 다시 $d_{model}$의 크기를 갖는 Embedding으로 만들어주는데 단순히 옆으로 붙이는 방식으로 $\cdot\times hd_{v}$로 묶어줍니다.
Yellow Block
Encoder와 Decoder 모두 Stack을 갖고, 반복적으로 작업이 수행되기 때문에 $\cdot \times hd_{v}$를 $\cdot\times d_{model}$로 맞춰줘야 되는데, Multi-Head에서 Linear 연산으로 논리적으로 쪼갯듯, Linear 연산을 통해 되돌려 주며, $W_{O}\in\mathbb{R}^{hd_{v}\times d_{model}}$ 가중치 행렬을 곱하여 해결할 수 있습니다.
Multi-Head Attention을 수식으로 요약하면 다음과 같습니다. $$\begin{align*}MutiHead(Q,K,V)&=Concat(head_1, \cdots, head_h)W_{O}\\head_i&=Attention\left(QW_{Q}^{(i)}, KW_{K}^{(i)}, VW_{V}^{(i)}\right)\\Attention(X,Y,Z)&=Softmax\left(\frac{XY^{\top}}{colsize(X)}+Masking\right)Z,\end{align*}$$ 여기에서 Masking 부분은 선택적으로 적용합니다.
Add & Norm.
Add & Norm. 논문의 flow chart에 등장하는 용어이고, 사실상 Residual Connection + Normalization Layer을 의미합니다. $$Add\text{ & }Norm(X)=Norm\left(X+sublayer(X)\right)$$위 수식에서 $X+sublayer(X)$ 부분이 Residual Connection에 해당하고, $Norm(\cdot)$이 Normalization Layer에 해당합니다. 추가적으로 sublayer는 어떤 input $X$가 통과되어 나온 출력값을 의미하는데, Transformer에서는 Attention Layer와 Feed Forward Layer가 됩니다. 이어서 Residual Connection과 Normalization Layer를 순차적으로 살펴보겠습니다.
Residual Connection은 input값에 residual을 더해준다는 의미로 $X+sublayer(X)$ 형태고, 여기에서 $sublayer(X)$를 residual로 봅니다. 어떤 데이터 X를 학습시킬 때, 모든 수치에 대해서 학습하기 보단 $sublayer(X)$에 대한 증분을 학습시키는 것이 효과적이라고 알려져있습니다. Transformer에서 첫 등장하는 Add & Norm.은 첫 Encoder의 Multi-Head Attention 바로 뒷 순서입니다. 바로 위에서 사용한 예시 문장 1 2 3 4의 상황에서는 해당 문장에 대한 Embedding Matrix가 $4\times d_{model}$이 Input인 X가 되고, Multi-Head Attention 결과가 $sublayer(X)$가 됩니다. 이를 합쳐주면 다시 $4\times d_{model}$ 크기의 입력값을 갖습니다.
Normailzation Layer는 널리알려진 것과 같으며, Residual Connection 결과인 $X+sublayer(X)$를 입력받습니다. $\tilde{X}=X+sublayer(X)$라고하면 Normailzation layer는 아래와 같이 정의됩니다. $$Norm(\tilde{X})=\gamma\hat{\tilde{X}}+\beta$$여기에서, $\gamma$, $\beta$는 학습할 weight paramter입니다. $\hat{\tilde{X}}$는 $\tilde{X}$의 row별 평균과 표준편차를 계산하고, 이를 이용한 표준화값으로 다음과 같습니다. $$\hat{\tilde{x}}_{ij}=\frac{\tilde{x}_{ij}-\mu_{i}}{\sqrt{\sigma^{2}_{i}+\epsilon}}$$여기에서 $\epsilon$은 분모가 0이 되는 것을 방지하기 위하여 아주 작은 값을 더해주는 용도로 사전에 정의되는 constant, $\mu_{i}$는 $i$ 행의 평균, $\sigma_{i}$는 $i$행의 표준편차입니다.
Position-wise Feed Forward Networks
Position-wise Feed Forward Networks는 Fig. 1의 Feed Forward에 해당합니다. Attention Layer는 문장을 하나의 데이터로 간주하여 각 토큰에 대한 Embedding Matrix를 하나로 생각했는데, Position-wise Feed Forward Networks에서는 각 토큰을 하나의 데이터로 간주한다는 의미로 Position-wise라는 말이 붙었습니다. 계산하는 방법은 아래와 같습니다. $$FNN(X)=relu\left(XW_{1}+b_{1}\right)W_{2}+b_{2}$$ 여기에서 $W_{1}\in\mathbb{R}^{d_{model}\times d_{ff}}$, $b_{1}\in\mathbb{R}^{d_{ff}\times 1}$, $W_{2}\in\mathbb{R}^{d_{ff}\times d_{model}}$, $b_{2}\in\mathbb{R}^{d_{model}\times 1}$의 크기를 갖습니다. 입력값인 $X$는 Attention Layer를 통과한 결과로 만약 $T$개의 토큰이 있었다면, $X\in\mathbb{R}^{T\times d_{model}}$의 크기를 갖습니다. 사실 말이 거창해서 그렇지 Feed Forward Networks와 동일합니다.
Flow
이제 모든 모듈을 살펴 봤습니다. Fig. 4와 함께 단계별로 살펴보고 마무리 하겠습니다. 먼저 Input과 Output을 Embedding matrix를 넣고, positional encoding을 더해줍니다. Output 입력시 주의할 점은 Seq2seq과 마찬가지고 Teacher forcing 방식을 이용하기 때문에 입력으로 이용될 Output Embedding 대비, 학습으로 이용될 (즉, label 역할을 하는) Output Embedding을 출력 대상의 토큰 값을 우측으로 한 스탭씩 미뤄준다는 점입니다. 그 다음엔 그림에 보이는 순서대로 먼저 Encoder에 Multi-Head Attention, Add & Norm, Feed-Forward, Add & Norm을 Encoder의 수 $N$만큼 반복합니다. 다음으론 Decoder에서는 Encoder $N$의 출력 값을 매 Decoder의 입력값으로 이용하고, 처음에는 Output Embedding으로, 두 번째 Decoder 부터는 이전 Decoder의 출력 값을 입력으로 받아, Masked Multi-Head Attention, Add & Norm, Multi-Head Attention, Add & Norm, Feed Forward, Add & Norm을 Decoder의 갯수 만큼 반복하고, 그 출력값을 이용하여 목적에 맞는 학습을 하는 순서입니다.
Summary
두 번의 포스팅으로 Transformer를 살펴봤습니다. 알고나면 단순한데, 단계가 많아 글이 길어졌습니다. Transformer의 등장이후 Neural Machine Translation이 크게 성장했습니다. 중요한 Framework이니 알아두면 큰 도움이 되지 않을까 생각합니다. 긴 글 읽어주셔서 감사합니다:)
References
Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
https://wikidocs.net/31379
'Deep Learning > Attention Mechanism' 카테고리의 다른 글
| Transformer (1) (0) | 2022.01.19 |
|---|---|
| Luong Attention (0) | 2021.12.09 |
| Bahdanau Attention (0) | 2021.11.24 |



댓글