이번 포스팅에서는 지난 Bahdanau Attention에 이어서 Luong Attention을 살펴보겠습니다.
Luong Attention
2014 Bahdanau et al.이 Neural Machine Translation (NMT)영역에 처음으로 Attention Mechanism을 적용하였습니다. Luong et al.은 "Effective Approaches to Attention-based Neural Machine Translation"에서 Bahdanau가 진행한 연구를 제외하면 NMT 영역에 Attention Mechanism 연구가 적다며, simplicity와 effectiveness를 염두한 방법을 제안합니다.Luong et al.의 출발점이 간단명료한 방향성을 갖고 있는 만큼 이번 포스팅에서는 Bahdanau Attention과 비교하여 어떤 부분이 발전되었는지를 확인하면서 진행해보려고 합니다.
Overview of Luong Attention
Luong Attention은 Query를 Decoder $t$ 시점의 hidden state로, Key, Value를 Encoder의 Hidden State의 전체 또는 일부를 사용하는 방법입니다. (Query, Key, Value에 대한 설명은 이전 포스팅에서 확인 할 수 있습니다.) 논문에서는 Encoder에 Stacked-LSTM을 적용하고, top-layer의 hidden state를 이용했지만, Encoder의 구조보단 Luong Attention의 관점이 중요하기에 RNN-based Architecture를 가정하고 아래 내용을 이어가겠습니다.
Bahdanau Attention과 비교하여 Attention Value를 구하는 과정에는 크게 세 가지 차이점이 있습니다. 첫 번째는 Query에 $t-1$시점 대신 $t$시점을 이용한다는 것이고, 두 번째는 Query와 Key의 관계를 계산하는 함수에 대한 차이점입니다. (아래에서 자세히 다루겠습니다.) 마지막으로는 아래 그림 (Fig. 1)에서 보라색 선으로 표현했는데, attention value를 Decoder의 $t$시점에서 $s_{t}$에 결합하여 사용하며, $t$시점의 input과 결합하여 사용하는 Bahdanau Attention과 차이가 있습니다.
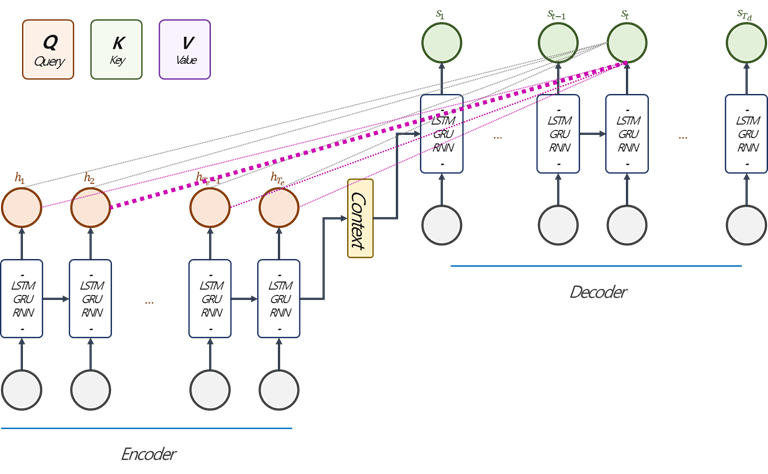
바로 앞 문단에서 Luong Attention은 Encoder hidden state의 일부 또는 전체를 사용한다고 했습니다. Luong et al.은 Hidden State의 전체를 참조하는 경우를 Global Attention, 일부를 참조하는 경우를 Local Attention이라 이름 지었습니다. Local Attention은 계산량을 줄이기 위한 노력의 일환 정도로 볼 수 있습니다. Global Attention, Local Attention 순으로 살펴보겠습니다.
Global Attention
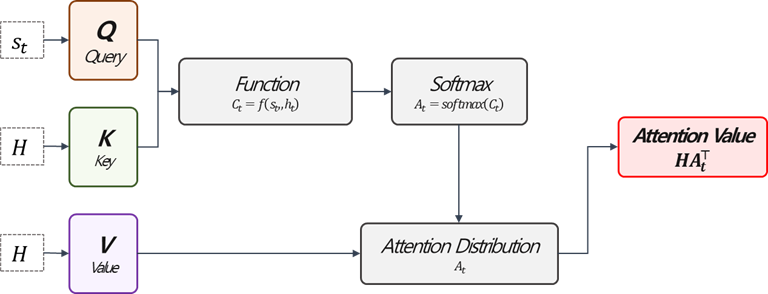
Global Attention은 Encoder 모든 시점의 hidden state 값을 참조하는 방법입니다. 때문에 Bahdanau Attention과 비교하여 Query와 Key의 관계를 계산하는 함수만 차이가 있고 같습니다. Luong et al.은 함수로 Dot , General, Concat 세 가지를 제안했습니다. $$C_{t}=score\left(s_{t}, H\right)=\begin{cases}s_{t}^{\top}H&\text{, dot}\\s_{t}^{\top}W_{a}H&\text{, general}\\v_{a}^{\top}tanh\left(W_{a}[h_{t};H]\right)&\text{, concat}\end{cases}$$ 여기에서 $H=\left[h_{1},h_{2},\cdots,h_{T_{e}}\right]$입니다. 즉, 말 그대로 Encoder의 모든 시점 $1,\cdots,T_{e}$ 모두를 참조합니다. $s_{t}$가 $(k\times 1)$, $H$는 $(k\times T_{e})$ (hidden state의 크기가 같다고 가정)이라고 하면, general의 경우$W_{a}$는 $(k\times k)$, concat의 경우 $v_{a}$는 $(2k \times 1)$, $W_{a}$는 $(2k\times T_{e})$가 됩니다. concat의 경우 $s_{t}$를 $h_{1},\cdots, h_{T_{e}}$아래 각각 붙여 넣기 때문에 $2k$라는 dimension이 나옵니다.
이후 $C_{t}(1\times T_{e})$를 softmax함수에 통과시켜 $A_{t}(T_{e}\times 1)$를 얻고, 다시 Value와 곱해 $HA_{t}^{\top}(k\times 1)$의 Attention Value를 얻습니다.
Local Attention
Local Attetion은 Encoder의 Hidden State의 일부만 참조하여 Attention Value를 계산하는 방법입니다. Decoder의 $t$시점의 Attention Value를 Local Attention으로 계산하기 위한 사전 준비로 Luong et al.은 $p_{t}$, Position Alignment Function과 $D$, Window Size를 제안하고, $p_{t}\pm D$ 범위에 있는 Encoder의 Hidden State만 참조합니다.
Window Size, D의 경우 경험적으로 선택하고, Position Alignment의 경우 두 가지 방법을 제안합니다.
Monotonic Alignment (Local-m)
Monotonic Alignment는 아주 단순하게 $p_{t}=t$로 정의하고, $p_{t}\pm D$ 범위에 있는 Encoder의 Hidden State만 이용해서 위 Global Attention과 동일하게 Attention Value를 계산합니다.
Predictive Alignment (Local-p)
윈도우 범위 안에 주어진 시점에 대하여 truncated-normal distribution의 값을 이용하여 가중치를 재분배하는 방법입니다. Position Alignment Function은 다음과 같이 정의합니다. $$p_{t}=T_{e} \cdot \sigma\left[v_{p}^{\top}tanh\left(W_{p}s_{t}\right)\right]\in\left[0, T_{e}\right],$$ 여기에서 $\sigma$는 sigmoid 함수를 의미합니다. 계산 결과로 $p_{t}$는 어떤 실수 값을 가지게 될 것이고, 사전에 정의된 $D$를 더하고 빼주면 $[p_{t}-D, p_{t}+D]$ 실수 구간을 얻을 수 있는데, 실수 구간상에 존재하는 정수에 대해서 아래의 함수를 적용합니다. $$a_{t}(H)=align(s_{t}, H)exp\left(-\frac{(s-p_{t})^{2}}{2(D/2)^{2}}\right)$$ 위에서 align은 global attention을 의미하고, $s$는 구간에 존재하는 정수를 의미합니다. 예를 들어 계산 결과 $p_{t}=4.6$를 얻고, $D=3$을 가정하면 $[1.6, 7.6]$구간에 정수는 $\{1,\cdots, 7\}$이 존재하고 해당 구간에서만 가중치가 있고, 나머진 0으로 참조하지 않는 방식입니다.
Concatenation (as an input)
Decoder $t$ 시점의 Attention Value를 $\tilde {h}_{t}$라고 하면, 이 결과를 Decoder의 Hidden State와 연결하여 $[\tilde{h}_{t};s_{t}]$를 만들고, 기존의 RNN-based architecture의 hidden state로 output을 계산하는 것과 동일하게 이용합니다. $$o_{t}=softmax\left(tanh\left(W_{c}[\tilde{h}_{t};s_{t}]\right)\right),$$ 이를 테면 위와 같이 사용합니다. 핵심은 Decoder의 Hidden State에 연결해서 쓴다는 점입니다. Bahdanau Attention의 경우 Input에 연결하는 점이 다릅니다.
Summary
지금까지 Luong Attention에 대해서 살펴보았습니다. Luong Attention, Global Attention의 Query와 key의 연관관계를 계산할 때 쓰이는 함수 중 dot함수가 가장 유명합니다. 애초에 간결하고, 효율적인 NMT 영역의 Attention Mechanism을 추구한 것과 같은 맥락을 합니다. 그래서 Luong Attention은 Dot Product Attention으로 불리기도 합니다. 이상 마치겠습니다.
긴 글 읽어주셔서 감사합니다:)
References
Luong, Minh-Thang, Hieu Pham, and Christopher D. Manning. "Effective approaches to attention-based neural machine translation."
arXiv preprint arXiv:1508.04025
(2015).
https://wikidocs.net/book/2155
'Deep Learning > Attention Mechanism' 카테고리의 다른 글
| Transformer (2) (0) | 2022.02.21 |
|---|---|
| Transformer (1) (0) | 2022.01.19 |
| Bahdanau Attention (0) | 2021.11.24 |



댓글