이번 포스팅에서는 Neural Machine Translation 영역에서 Attention Mechanism의 효시가된 Bahdanau Attention에 대해서 다뤄보겠습니다. Bahdanau Attention은 2014에 처음 등장한 이후, Attetion이라는 새로운 접근법 아래 활발한 연구와 발전을 이루며 기계 번역이 크게 성장했습니다.
Why Attention?
지난 포스팅에서 Seq2Seq을 살펴봤습니다. 고정된 크기의 input과 output을 처리하던 전통적인 Recurrent Neural Networks에서 가변적 길이의 input, output을 처리할 수 있는 방법이었습니다. Seq2seq은 크게 Encoder Part와 Decoder Part로 구분되어 있습니다. Encoder에서는 Input을 받아 대응하는 Fixed-length Context Vector를 출력하는 역할을, Decoder는 Fixed-length Context Vector를 시작으로 순차적으로 Input에 대한 Output을 생성하는 역할을 합니다.
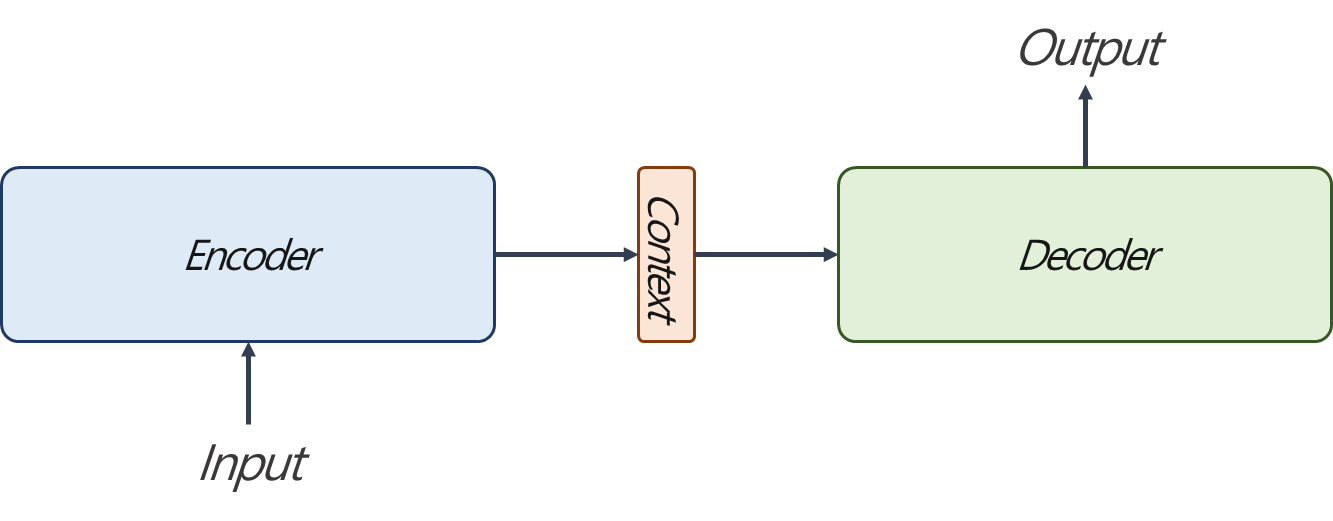
Seq2seq 구조를 단순화 하면 위 fig.1과 같습니다. Encoder 부분을 확대해보면, 시간 순서에 따라 input을 순차적으로 입력받습니다. 예를 들어 "I like an apple."라는 문장이 있다면 I, like, an, apple, <eos>를 one-hot encoding vector 또는 Embedding vector를 입력을 받습니다. 이어서 이에 대한 context vector를 출력합니다.

다시 표현해보면 Fig. 2와 같습니다. Encoder Part의 Encoding은 LSTM, GRU의 hidden layer의 값을 이용합니다. 물론 다른 구조가 적용되어도 무관합니다. 눈치채셨겠지만, 마지막에 fixed-length context vector에서 4개의 단어에 대한 정보를 모두 함축하고 있습니다. 눈치채셨겠지만, 문장의 길이가 길다면, context vector에서 충분히 많은 정보를 압축하기를 기대하기 어렵습니다. Attention Mechanism은 Encoder의 각 스탭의 hidden layer의 값을 상황에 따라서 집중(attention)하여 사용할 수 있는 방법을 제안합니다.
What Attention?
Attention은 주어진 쿼리(Query)에 대해서, 키(Key)에 대한 값(Value)를 이용하여 Query의 답을 얻기위해서 어떤 Key를 살펴봐야 되는지 계산해주는 함수입니다. 조금 구체적으로 풀어쓰면, Query는 attention의 주체를 의미하고, Key는 Query에 대한 attention의 기여도를 계산할 대상, Value는 Attention 크기를 계산하기 위한 값입니다.최종적으로느 Q, K로 얻어진 Weight를 이용하여, Value의 Weighted sum으로 Attention Value가 출력됩니다. (Context Vector라고 불리기도 합니다.)
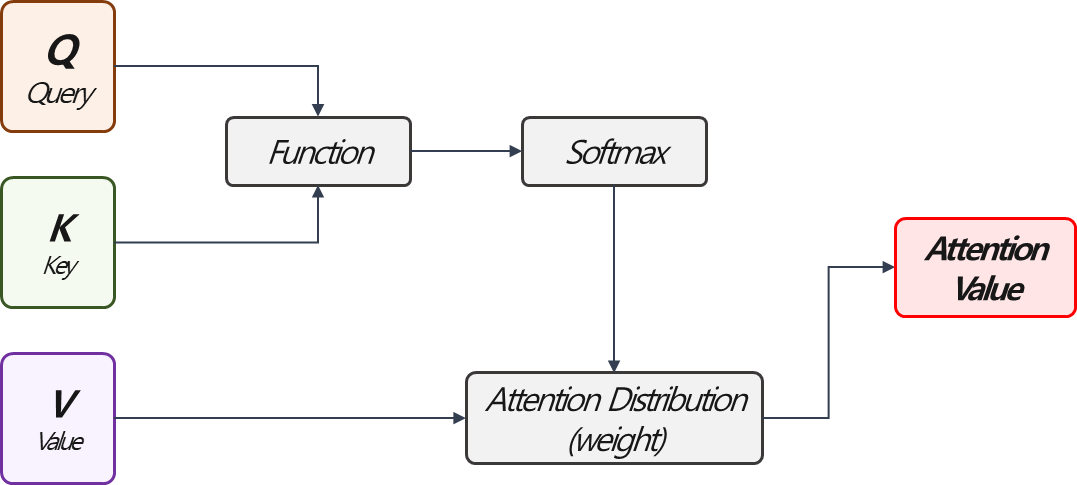
위 그림은 대략적인 Attention Mechanism의 흐름을 표현했습니다. Q, K, V에 어떤 값이 대응되고, function에 따라서 다양한 계산방법이 존재합니다.
예를 들어 Seq2seq 구조에서 Attention value를 계산하는 상황을 생각해보겠습니다. Decoder의 값을 계산할 때 아주 과거의 정보를 반영하기 위해서 Attention Value가 필요하다면, Query는 Decoder의 Hidden State, Key는 Encoder의 Hidden State가 되고, 이에 대한 Weight는 Query와 Key의 관계를 반영한 함수와 Softmax를 이용하여 계산합니다. 이어서 Value 또한 Encoder의 Hidden State이고 앞서 얻은 weight를 이용하여 weighted sum를 계산한 것을 Attention Value 또는 Context Vector라고 합니다.
Bahdanau Attention
Overview of Bahdanau Attention
Bahdanau Attention은 Query를 Decoder $t-1$ 시점의 hidden state, Key, Value를 Encoder의 모든 시점의 hidden state로 이용하는 방법입니다. 원 논문에서는 Encoder를 Bidirectional RNN을 적용했지만, 어쨋든 hidden layer를 활용한다는 측면에서 같습니다. Bahdanau Attention을 자세히 살펴보겠습니다.
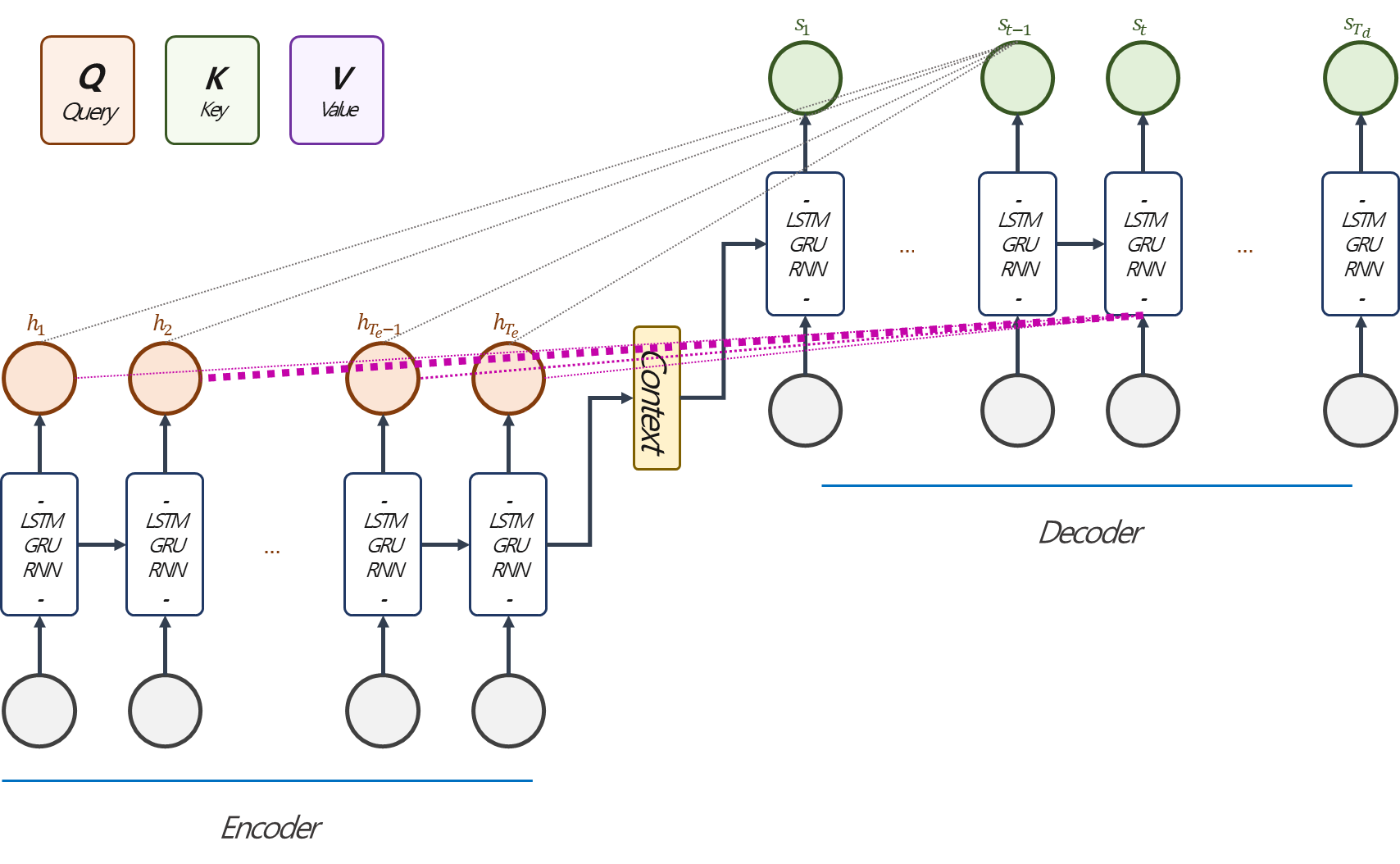
Bahdanau Attention의 전체적인 흐름은 위 fig. 4와 같습니다.
Bahdanau Attention
구체적으로 Bahdanau Attention Value를 계산해보겠습니다. $$\text{Attention Value}=H\text{softmax}\left[W_{a}^{\top}tanh\left(W_{q}s_{t-1}+W_{k}H\right)\right]^{\top},$$여기에서 $H=\left[h_{1},\cdots,h_{T_{e}}\right]$입니다. 앞서 살펴본 Mechanism에 대입하면 아래와 같은 상황입니다.
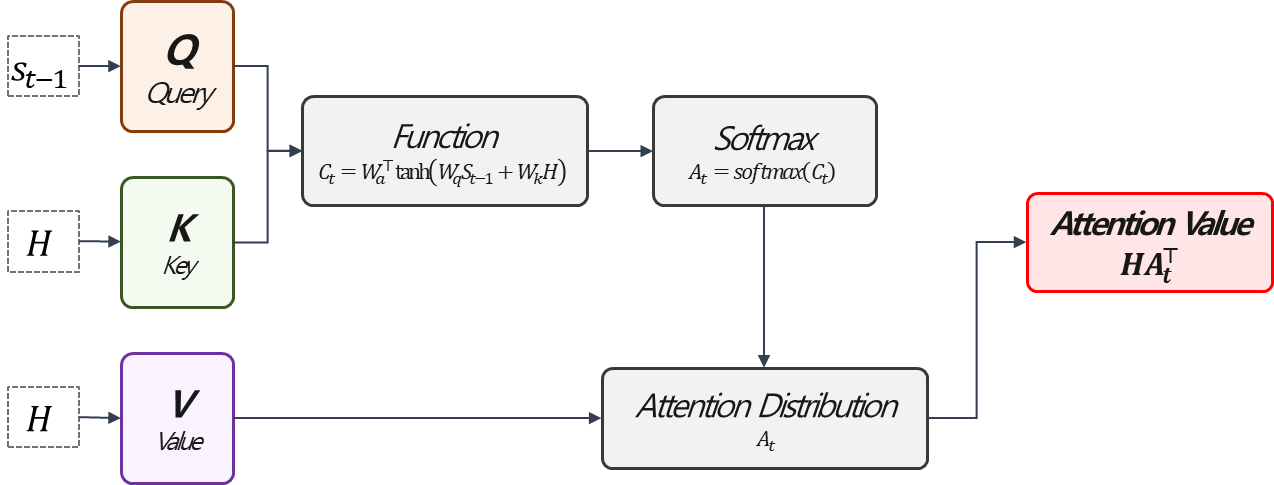
먼저 Function Part입니다. Query,Key를 입력받아서 둘의 상호작용을 추출하는 과정입니다. Bahdanau Attention에서는 위와 같은 과정을 거쳐 계산됩니다. 여기서 $+$를 조심해야 됩니다. Function에 대한 계산 결과는 Query는 $W_{q}:(k\times k)$, $s_{t-1}:(k\times 1)$로 $(k\times 1)$의 크기를 갖고, Key의 경우 $W_{k}:(k\times k)$, $H:(k\times T_{e})$로 $(k\times T_{e})$ 더하여 $(k\times T_{e})$를 출력합니다. (여기에서 $k$는 hidden layer의 vector size입니다.) 때문에 여기서 $+$는 columnwise sum을 의미합니다. 즉, Query의 연산 결과 벡터를, Key에 대한 연산결과에 각각 더해줍니다. 이어서 tangent hyperbolic 함수에 통과 시킨뒤 $W_{a}:(k\times 1)$를 곱해, 중요도 벡터 $C_{t}:(1 \times T_{e})$를 얻게됩니다. 이를 softmax 함수에 rowwise로 통과 시키고 $A_{t}:(1\times T_{e})$ Attention Distribution을 얻어, 이를 Value와 곱하고 $HA_{t}^{\top}:(k\times 1)$의 Attention Value를 산출하게 됩니다. 결국 Attention Score는 Query, Key의 관계를 반영한 가중치를 계산하고, 이를 이용하여 Value Vector의 weighted average를 얻는 것 으로 해석할 수 있습니다.
Conatenation (as an input)
이제 마무리입니다. Fig. 4를 자세히 보셨다면 눈치채셨겠지만, 이렇게 얻어진 Attention Value, $\tilde{h}_{t}$는 Decoder의 $t$시점의 input과 결합되어서 이용됩니다. 즉, seq2seq에서 decoder의 $t$시점에 $y_{t-1}$이 input으로 이용됐다면, Bahdanau Attention에서는 $[\tilde{h}_{t};y_{t-1}]$을 사용합니다.
Summary
이번 포스팅에서는 Bahdanau Attention을 살펴 봤습니다. 사실 Bahdanau Attention은 조금 오래된 방법이지만, Attention의 컨샙을 RNN에 적용했다는 점에 큰 기여가 있습니다. 때문에 이번 포스팅에서 강조하고 싶은 것은 What Attention?에 정리된 내용인 커다란 틀에서 Attention이 계산되는 방식입니다. 이상으로 포스팅을 마치겠습니다.
긴 글 읽어주셔서 감사합니다. :)
Reference
Bahdanau, Dzmitry, Kyunghyun Cho, and Yoshua Bengio. "Neural machine translation by jointly learning to align and translate."
arXiv preprint arXiv:1409.0473
(2014).
https://wikidocs.net/book/2155
'Deep Learning > Attention Mechanism' 카테고리의 다른 글
| Transformer (2) (0) | 2022.02.21 |
|---|---|
| Transformer (1) (0) | 2022.01.19 |
| Luong Attention (0) | 2021.12.09 |



댓글