Gated Recurrent Units (GRU)
GRU는 게이트 메커니즘이 적용된 RNN 프레임워크의 일종으로 LSTM에 영감을 받았고, 더 간략한 구조를 가지고 있습니다. 아주 자랑스럽게도 한국인 조경현 박사님이 제안한 방법입니다. (Cho et al., 2014) GRU는 LSTM에 영감을 받은 만큼 굉장히 유사한 구조로 LSTM을 제대로 이해하고 있으면 쉽게 이해할 수 있습니다. LSTM은 이곳에 자세히 정리되어 있으니 가볍게 읽고 이어질 포스팅을 읽으면 더 유익할 것 같습니다.
GRU의 작동원리
LSTM과 같은 그림을 이용해서 GRU를 이해해보겠습니다. 전체적인 흐름은 아래와 같습니다.

뭔가 되게 복잡해보이지만, LSTM을 이해하셨다면 생각보다 단순합니다. 하나씩 단계별로 살펴보도록 하겠습니다.
1. Reset Gate
Reset Gate는 과거의 정보를 적당히 리셋시키는게 목적으로 sigmoid 함수를 출력으로 이용해 $(0, 1)$ 값을 이전 은닉층에 곱해줍니다.

직전 시점의 은닉층의 값과 현시점의 정보에 가중치를 곱하여 얻을 수 있고 수식으로 나타내면 다음과 같습니다. $$r^{(t)}=\sigma\left(W_{r}h^{(t-1)}+U_{r}x^{(t)}\right)$$
2. Update Gate
Update Gate는 LSTM의 forget gate와 input gate를 합쳐놓은 느낌으로 과거와 현재의 정보의 최신화 비율을 결정합니다. Update gate에서는 sigmoid로 출력된 결과($u^{(t)}$)는 현시점의 정보의 양을 결정하고, 1에서 뺀 값($1-u^{(t)}$)는 직전 시점의 은닉층의 정보에 곱해주며, 각각이 LSTM의 input gate와 forget gate와 유사합니다.

이를 수식으로 나타내면 다음과 같습니다. $$u^{(t)}=\sigma\left(W_{u}h^{(t-1)}+U_{u}x^{(t)}\right)$$
3. Candidate
현 시점의 정보 후보군을 계산하는 단계입니다. 핵심은 과거 은닉층의 정보를 그대로 이용하지 않고 리셋 게이트의 결과를 곱하여 이용해줍니다.
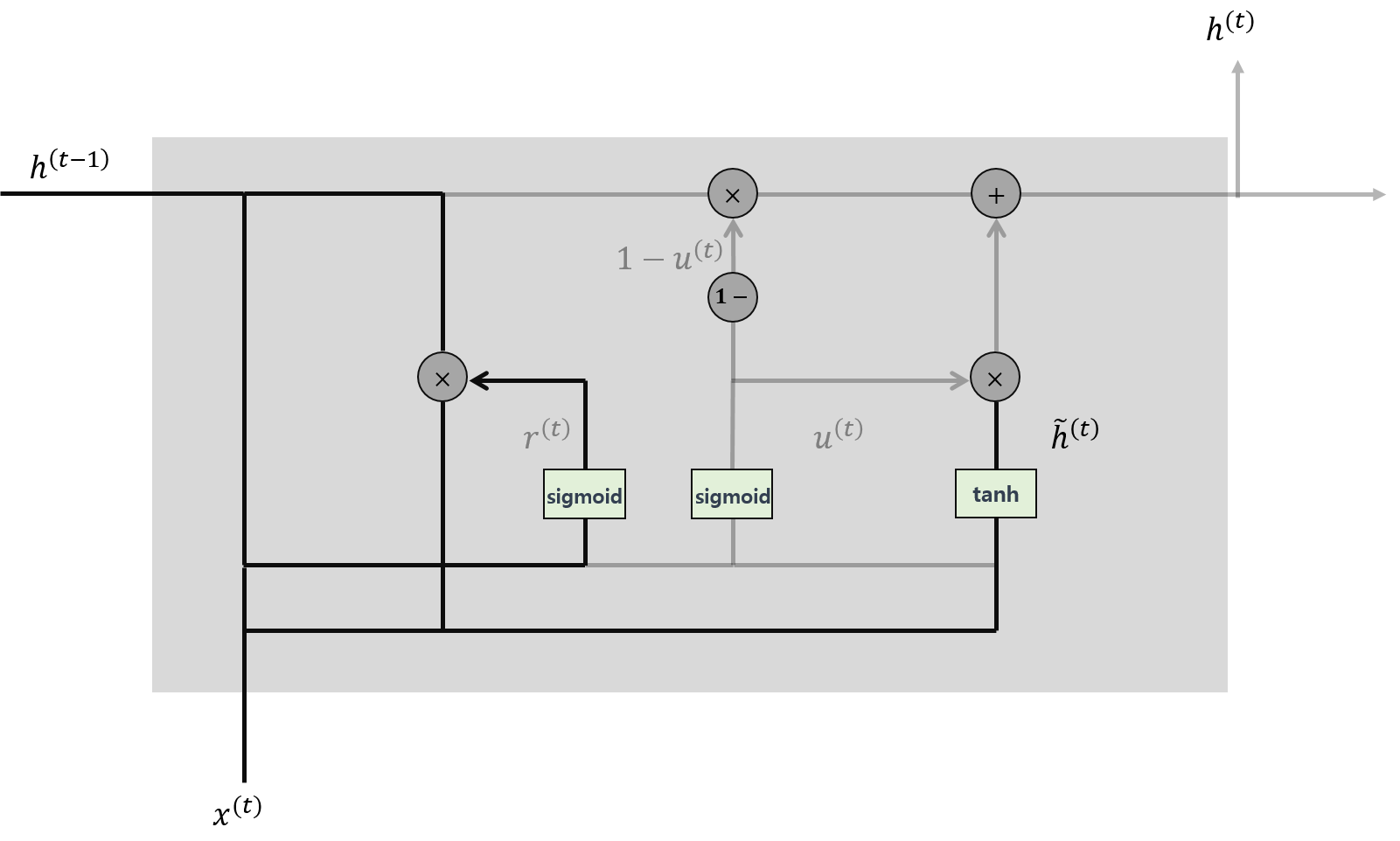
수식으로 나타내면 다음과 같습니다. $$\tilde{h}^{(t)}=\tau\left(Wh^{(t-1)}*r^{(t)}+Ux^{(t)}\right)$$ 여기에서 $\tau$는 tangent hyperbolic이고, $*$은 pointwise operation입니다.
4. 은닉층 계산
마지막으로 update gate 결과와 candidate 결과를 결합하여 현시점의 은닉층을 계산하는 단계입니다. 앞에 말했다시피 sigmoid 함수의 결과는 현시점 결과의 정보의 양을 결정하고, 1-sigmoid 함수의 결과는 과거 시점의 정보 양을 결정합니다.

수식으로 정리하면 아래와 같습니다. $$h^{(t)}=(1-u^{(t)})*h^{(t-1)}+u^{(t)}*\tilde{h}^{(t)}$$
GRU 정리

LSTM과 구조상 큰 차이도 없고, 분석결과도 큰 차이가 없는 것으로 알려져있습니다. 분석 결과가 큰 차이가 없다는 것은 같은 목적에서 성능상의 큰 차이가 없다는 의미가 아니라, 주제별로 LSTM이 좋기도, GRU가 좋기도 하다는 의미입니다. 다만 GRU가 학습할 가중치가 적다는 것은 확실한 이점입니다. 아마 LSTM을 보고오셨다면 쉽게 이해하셨을거라고 생각합니다. 마지막으로 수식을 한 군데 모으며 포스팅을 마치겠습니다 :) $$\begin{align*}r^{(t)}&=\sigma\left(W_{r}h^{(t-1)}+U_{r}x^{(t)}\right)\\u^{(t)}&=\sigma\left(W_{u}h^{(t-1)}+U_{u}x^{(t)}\right)\\\tilde{h}^{(t)}&=\tau\left(Wh^{(t-1)}*r^{(t)}+Ux^{(t)}\right)\\h^{(t)}&=(1-u^{(t)})*h^{(t-1)}+u^{(t)}*\tilde{h}^{(t)}\end{align*}$$
References
- Cho, Kyunghyun, et al. "Learning phrase representations using RNN encoder-decoder for statistical machine translation." arXiv preprint arXiv:1406.1078 (2014).
- Wikipedia contributors. "Gated recurrent unit." Wikipedia, The Free Encyclopedia. Wikipedia, The Free Encyclopedia, 12 Jul. 2019. Web. 25 Aug. 2019.
'Deep Learning > Recurrent Neural Networks' 카테고리의 다른 글
| Seq2seq Model (Sequence to Sequence Model) (0) | 2020.04.20 |
|---|---|
| RNN Tensorflow + Keras (10) | 2019.12.07 |
| Long Short-Term Memory (LSTM) (9) | 2019.08.15 |
| Recurrent Neural Networks (RNN) (0) | 2019.08.13 |




댓글