RNN이란?
Recurrent Neural Networks(RNN)은 순차적 데이터를 분석하기 위한 딥러닝 구조로 Rumelhart et al., 1986에 근간을 두고있습니다. Deep Neural Network (DNN)은 은닉층 내 노드간에 연결이 안되어 있지만, RNN은 은닉층 내 노드를 연결하여, 이전 스텝의 정보를 은닉층 노드에 담을 수 있도록 구성했습니다.

위 그림에서 볼 수 있듯 $x^{(1)}$으로 부터 $h^{(1)}$을 얻고 다음 스텝에서 $h^{(1)}$과 $x^{(2)}$을 이용하여 과거 정보와 현재 정보 모두를 반영할 수 있습니다. 은닉층의 노드의 값을 $t+1$ 시점으로 넘겨주고, $t+1$ 시점의 입력을 받아서 계산하는 작업을 반복적으로 진행하여 "Recurrent" 이름이 붙었습니다. 반복적으로 진행되는 구조를 축약하여 위 그림의 우측처럼 나타낼 수 도 있습니다.
가중치 공유
RNN의 학습 가중치는 시작 층과 도착 층에 따라 크게 세 가지, $U$, $W$, $V$로 분류됩니다.
- $U$: 입력층 $\rightarrow$ 은닉층
- $W$: $t$ 시점 은닉층 $\rightarrow$ $t+1$ 시점 은닉층
- $V$: 은닉층 $\rightarrow$ 출력층
가중치 $U$, $W$, $V$는 모든 시점에서 동일합니다. 즉 가중치를 공유합니다. 가중치 공유는 두 가지 이점이 있습니다.
- 학습에 필요한 가중치의 수를 줄일 수 있다.
- 데이터별 시간의 길이 $T$에 유연하다.
가중치를 공유하면 모든 edge에 가중치를 다르게 주는 것보다 학습할 가중치가 줄어드는 것은 직관적으로 알 수 있습니다. 데이터별 시간의 길이 $T$에 유연함을 이해하기 위해서, 단어를 완성해주는 RNN을 고려해보겠습니다. (예를 들어, "hell" 다음 "o", "kin" 다음 "g", "Exper" 다음 t를 예측)

시간의 길이 $T$에 유연하다는 것은1개의 모형으로 hell의 o를, kin의 g를, exper의 t를 예측가능하다는 것 입니다. 어짜피 같은 가중치를 곱해주고, 은닉층에 단어의 과거 정보가 포함되어 있어, 위 예제 단어의 길이 5, 4, 6에 무관하게 같은 모형을 적용시킬 수 있습니다.
RNN Architectures
위에서 살펴보았듯 RNN은 입력과 출력 값의 길이에 자유로운 모형입니다. Input과 Output의 형태에 따라 아래처럼 다양한 구조로 RNN을 구성할 수 있습니다.
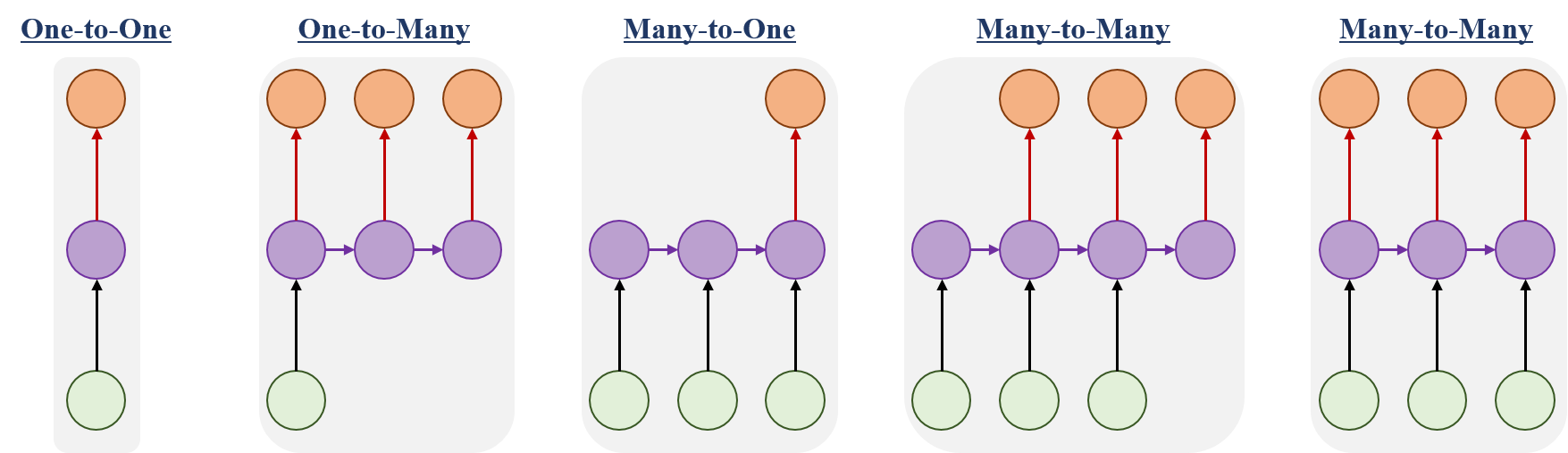
- One-to-One: Vanlina Neural Networks, 은닉층이 1층인 신경망 모형
- One-to-Many: Image를 입력으로 받아, Image 속 대상에 이름을 붙이는 모형
- Many-to-One: word sequence를 입력으로 받아, 감정 분류를 해주는 모형
- Many-to-Many: 기계 번역 모형, word sequence를 입력으로 받아, word sequence을 출력
- Many-to-Many: 비디오의 frame을 입력으로 받아 frame 속 대상에 이름을 붙이는 모형
RNN 동작원리
이제 RNN의 동작원리와 역전파 방법에 대해서 이해하면 RNN을 이해할 수 있습니다. RNN의 역전파 알고리즘인 BPTT (Back Propagation Through Time)는 내용이 방대하여 다음 포스팅에서 따로 다루도록하고, 이번 포스팅에서는 RNN이 구체적으로 어떻게 동작하는지 살펴보고 이번 포스팅을 마무리하겠습니다.
제일 간단한 형태의 RNN부터 시작해보겠습니다. 입력층, 은닉층의 노드의 수가 1개이고, 출력층이 $K$개 노드가 있는 경우입니다. 즉, $x^{(t)}\in\mathbb{R}$, $h^{(t)}\in\mathbb{R}$, $o^{(t)}\in\mathbb{R}^{K}$과 같습니다. 때문에 가중치 $W$, $U$는 스칼라가, $V\in\mathbb{R}^{K\times 1}$ 됩니다.

$t$ 스텝에서의 RNN의 계산이 어떻게 이루어지는지 살펴보겠습니다.
- 은닉층: 은닉층을 계산에는 $x^{(t)}$와 $h^{(t-1)}$이 필요하며, $$\begin{align*}h^{(t)}&=\tau(a^{(t)})\\a^{(t)}&=Wh^{(t-1)}+Ux^{(t)}\end{align*}$$로 계산할 수 있습니다. ($\tau$: hyperbolic tangent) 편의상 bias는 제외 했습니다.
- 출력층: 출력층은 DNN과 계산하는 방법이 같습니다. $$o^{(t)}=softmax\left(Vh^{(t)}\right)$$
위 내용을 일반화해보겠습니다 $x$, $h$, $o$가 의미하는 바는 위와 같고, $x\in\mathbb{R}^{D}$, $h\in\mathbb{R}^{J}$, $o\in\mathbb{R}^{K}$, 즉, 각각의 노드의 수가 $D$, $J$, $K$인 상황입니다. 따라서 가중치 행렬의 차원은 $U\in\mathbb{R}^{J\times D}$, $W\in\mathbb{R}^{J\times J}$, $V\in\mathbb{R}^{K\times J}$가 됩니다. 도식화해보면 아래와 같습니다.

계산하는 방법은 은닉층과 입력층의 노드가 1개일 때와 가중치가 스칼라에서 행렬로 바뀐것 말고는 동일하여 생략하도록 하겠습니다.
이상으로 RNN 포스팅을 마치고 다음 포스팅에서는 LSTM과 BPTT로 찾아뵙겠습니다 :)
References
- Williams, Ronald J.; Hinton, Geoffrey E.; Rumelhart, David E. (October 1986). "Learning representations by back-propagating errors". Nature. 323(6088): 533–536.
'Deep Learning > Recurrent Neural Networks' 카테고리의 다른 글
| Seq2seq Model (Sequence to Sequence Model) (0) | 2020.04.20 |
|---|---|
| RNN Tensorflow + Keras (10) | 2019.12.07 |
| Gated Recurrent Units (GRU) (8) | 2019.08.15 |
| Long Short-Term Memory (LSTM) (9) | 2019.08.15 |




댓글