이번 포스팅에서는 강화학습의 가치함수를 추정하고 순차적 의사결정을 할 수 있는 tabular methods (DP ((1), (2)), MC ((1), (2)), TD)을 비교해보도록 하겠습니다.
Update Rules
먼저 핵심이 되는 업데이트 규칙을 살펴보겠습니다. 하기 업데이트 규칙은 control에 대한 것만 기술했습니다. 구체적인 내용 및 prediction은 위에 걸어둔 링크를 타고 들어가면 확인할 수 있습니다.
[ Dynamic Programming ] $$v(s)\leftarrow \underset{a}{\operatorname{max}}\sum_{s',r}\mathbb{P}\left(s',a\left|\right. s,a\right)\left[r+\gamma v(s')\right]$$[ Monte Carlo ] $$q(s,a)\leftarrow \frac{1}{t}\sum_{k=1}^{t}q_{k}(s,a)$$[ Temporal Difference (on-policy) Sarsa ] $$q(s,a)\leftarrow q(s,a)+\alpha\left[r'+\gamma q(s',a')-q(s,a)\right]$$[ Temporal Difference (off-policy) Q-learning ] $$q(s,a)\leftarrow q(s,a)+\alpha\left[r+\gamma\underset{a}{\operatorname{max}}q(s',a)-q(s,a)\right]$$Tabular methods는 크게 위 네 가지로 구분할 수 있습니다. 위 네 가지 방법을 Trajectory의 관점에서 그리고 Bootstrap, Sampling의 관점에서 비교해보겠습니다.
View of Trajectory
Trajectory는 상태, 행동, 보상의 sequence를 의미합니다. 즉 $S_{0},A_{0},R_{1},S_{1},A_{1},\cdots$와 같습니다. DP, MC, TD, Q-learning의 업데이트는 trajectory 일부 또는 전체를 이용하는데 이를 tree 구조로 표현해보면 아래와 같습니다.
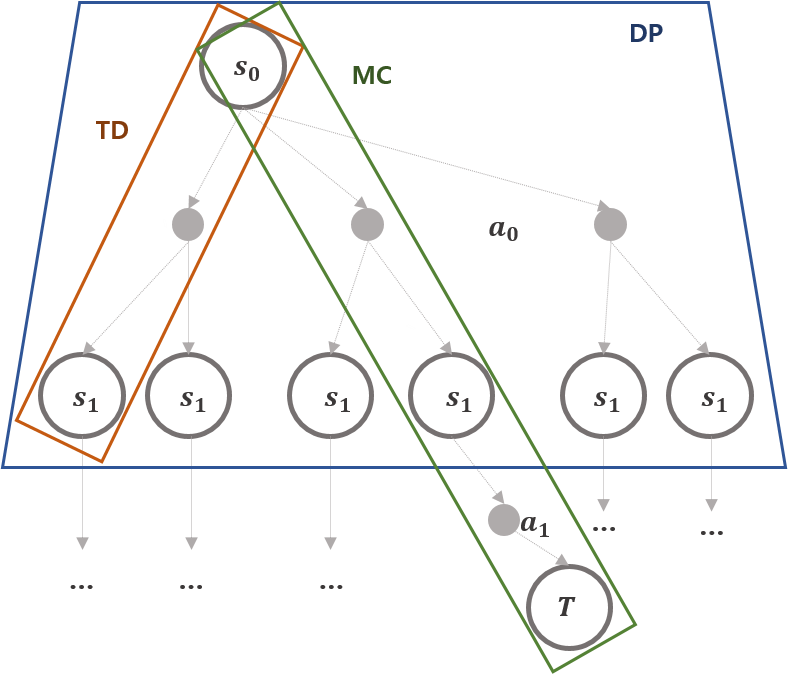
위 그림의 TD는 1-step TD를 의미합니다. Step의 크기에 따라서 MC와 TD, DP로 구분할 수 있습니다. (자연스럽게 step의 크기를 무한히 키우면 TD는 결국 MC와 같습니다.) MC는 terminal state에 도착할 때 까지 모든 정보를 사용하며, TD와 DP는 1-step 정보만 이용합니다. TD와 DP는 다시 $t+1$시점의 정보를 모두 사용하는가와 실제 행동 사용 여부로 구분지을 수 있습니다. DP는 환경을 알기 때문에 $\mathbb{P}$ $t$ 시점의 고정된 상태 기준 $t+1$ 시점에 가능한 행동과 대응하는 모든 상태 정보에 대한 보상의 가중 평균으로 업데이트하고, TD는 $t$ 시점에서 $\epsilon$-greedy한 행동을 선택하고 이를 $t+1$시점의 정보로 이용합니다.
Bootstrap vs. Sampling
Bootstrap은 $t$시점 상태함수를 업데이트할 때, $t$ 시점의 상태함수 값을 알 수 없기 때문에 $t-1$ 시점의 상태함수를 이용하여 이를 업데이트하는 방법을 의미합니다. Sampling은 환경을 알 수 없기 때문에 랜덤하게 혹은 $\epsilon$-greedy하게 행동을 취하며 얻어진 trajectory의 보상을 이용하여 가치함수를 업데이트하는 방법입니다. Bootstrap의 대표적인 방법은 DP가, Sampling의 대표적 방법에는 MC가 있고, TD는 Boostrap과 Sampling 모두에 해당합니다. DP와 MC는 Bootstrap, Sampling이 명확하니 생략하기로 하고, TD는 각각 어디에 적용되는지 살펴보고 마무리하겠습니다.
[ TD update Rule ] $$q(s,a)\leftarrow q(s,a)+\alpha\left[r'+\gamma q(s',a')-q(s,a)\right]$$위 식의 $t+1$시점 행동인 $a'$은 $q(s,a)$의 $\epsilon$-greedy한 행동 선택의 결과, 즉 sampling의 결과입니다. $t+1$ 시점의 상태함수를 알 수 없기 때문에 $q(s',a')$를 적용, 즉 bootstrap 방식이 적용됐습니다. 이렇듯 TD는 Bootstrap과 Sampling 모두가 적용된 방법으로 TD의 off-policy 방법인 q-learning이 가장 많이 적용되고 있습니다. 실제로 deepmind의 breakout도 q-learning이 적용됐습니다. 정확히는 tabular q-learning이 아닌 approximated q-learning이 적용되었고 다음 포스팅부터 살펴볼내용입니다.
Limitation of Tabular Methods
지금까지 tabular method를 살펴봤습니다. Tabular Methods를 공부하며 눈치채셨겠지만 상태공간의 크기 또는 행동공간의 크기가 커지면 모든 경우에 대한 가치함수를 메모리에 저장하고 있어야함으로 한계점이 존재합니다. 이를 극복하기 위하여 Tabular Method는 Approximation Method로 확장됩니다. 다음 포스팅부턴 Approximation Method를 살펴보겠습니다. 감사합니다:)
References
- Sutton, Richard S., and Andrew G. Barto. Introduction to reinforcement learning. Vol. 2. No. 4. Cambridge: MIT press, 1998.
- Mnih, Volodymyr, et al. "Playing atari with deep reinforcement learning." arXiv preprint arXiv:1312.5602 (2013).
- Mnih, Volodymyr, et al. "Human-level control through deep reinforcement learning." Nature 518.7540 (2015): 529.
'Reinforcement Learning > Tabular Methods' 카테고리의 다른 글
| Tabular Temporal Difference Learning - Sarsa, Q-learning, Double Q-learning (0) | 2019.11.11 |
|---|---|
| Monte Carlo Methods in RL (2) (2) | 2019.11.01 |
| Monte Carlo Methods in RL (1) (0) | 2019.10.30 |
| Dynamic Programming in RL (2) (0) | 2019.10.16 |
| Dynamic Programming In RL (1) (0) | 2019.10.11 |




댓글