직전 포스팅에서는 DP를 이용하여 주어진 정책아래 가치함수를 어떻게 계산하고, 계산된 가치함수 기반 정책 개선을 어떻게 이뤄낼 수 있는지 살펴보았습니다. 이번 포스팅에서는 가치함수의 평가, 개선을 반복적으로 수행하여 최적 정책을 찾는 알고리즘인 정책반복(Policy Iteration)과 가치반복(Value Iteration)에 대하여 살펴보겠습니다.
정책 반복 (Policy Iteration)
정책 반복은 앞서 다룬 정책 평가와 개선을 반복하는 방법입니다. 이를 수식화 하면 다음과 같습니다. $$\pi_{0}\stackrel{E}{\longrightarrow}v_{\pi_{0}}\stackrel{I}{\longrightarrow}\pi_{1}\stackrel{E}{\longrightarrow}v_{\pi_{1}}\stackrel{I}{\longrightarrow}\cdots\stackrel{I}{\longrightarrow}\pi_{*}\stackrel{E}{\longrightarrow}v_{*}$$ 여기에서 $E$는 평가(Evaluation)을, $I$는 개선(Improvement)을 의미합니다. 이런식으로 단순히 평가와 개선을 반복하는 방법을 정책 반복 (Policy Iteration)이라고 부릅니다. 이를 pseudocode로 나타내보면 아래와 같습니다.

가치 반복 (Value Iteration)
정책 반복의 가장 큰 단점은 정책 평가 단계가 수렴할 때 까지 진행되기 때문에 시간이 많이 걸린다는 점입니다. 즉, 정책 단계에서 너무 많은 sweep이 문제가 되는 것 입니다. 가치 반복(value iteration)은 정책 평가 단계에서 단 한 번의 sweep 이후, 바로 정책 개선을 시키는 반복법입니다. 이를 수식으로 나타내면 $$\begin{align*}v_{k+1}(s)&=\underset{a}{\operatorname{max}}\mathbb{E}\left[\left.R_{t+1}+\gamma v_{k}(S_{t+1})\right|S_{t}=s, A_{t}=a\right]\\&=\underset{a}{\operatorname{max}}\sum_{s',r}\mathbb{P}(s',r|s,a)\left[r+\gamma v_{k}(s')\right]\text{, }\forall s\in\mathcal{S}\end{align*}$$ 즉, 평가와 개선의 1 sweep을 하나로 결합시킨 것이 가치 반복입니다. 이어서 pseudocode를 살펴보겠습니다.

정책 반복 v.s 가치 반복
앞서 두 가지 반복법으로 최적 정책을 찾는 방법에 대하여 살펴보았습니다. 두 방법을 grid world 문제에 적용하며 비교해보도록 하겠습니다.

위 예제는 그리드 월드 입니다. $(1, 1)$, $(4,4)$는 종료 상태이며 두 곳을 제외한 어디에서도 시작할 수 있습니다. 각 상태에서는 좌, 우, 위, 아래로 이동가능하며 낭떠러지로 갈 경우에는 제자리로 돌아옵니다. 이때 보상은 종료상태를 도착할 경우를 제외하고는 모두 -1이며, 종료 상태에 도착하면 1을 얻습니다. 마지막으로 감가율은 1로 설정했습니다.
위 figure 3에서 윗 첫 줄은 정책 반복의 2번의 반복 결과입니다. 큰 루프는 두 번 반복 했지만 첫 반복에서는 540 sweep이 발생했으며, 두 반복 통틀어서는 수렴까지 총 602 sweep이 발생합니다. 아래 첫 그림은 가치 반복의 결과입니다. 42번의 sweep 만에 최적 정책을 찾은 것을 확인 할 수 있고, 정책 반복에 비하여 효율적입니다.
Generalized Policy Iteration (GPI)
정책 반복과 가치 반복 모두 정책을 평가하고 개선하는 상호작용으로 최적 정책을 찾는 알고리즘이었습니다. 이렇게 정책의 평가, 개선의 상호작용을 이용하여 최적 정책을 찾는 것을 Generalized Policy Iteration이라고 부릅니다. 이전 포스팅에서 DP는 model-based 방법이라고 말씀드렸습니다. 즉 상태전이확률 $\mathbb{P}(s',r|s,a)$를 알고 있어야 적용할 수 있습니다. 나아가 상태전의확률을 알고 있으면 행동가치함수가 상태가치함수 $v(s)$로 표현가능하기 때문에 상태가치함수만 계산하면 최적정책을 찾을 수 있었습니다. 하지만 model을 모를 경우에는 model-free한 방법(다음 포스팅에서 다룰 예정입니다.)을 적용해야합니다. 이 경우에는 행동가치함수기반 GPI를 적용하게 됩니다. 위 내용을 도식화해보면 다음과 같습니다.
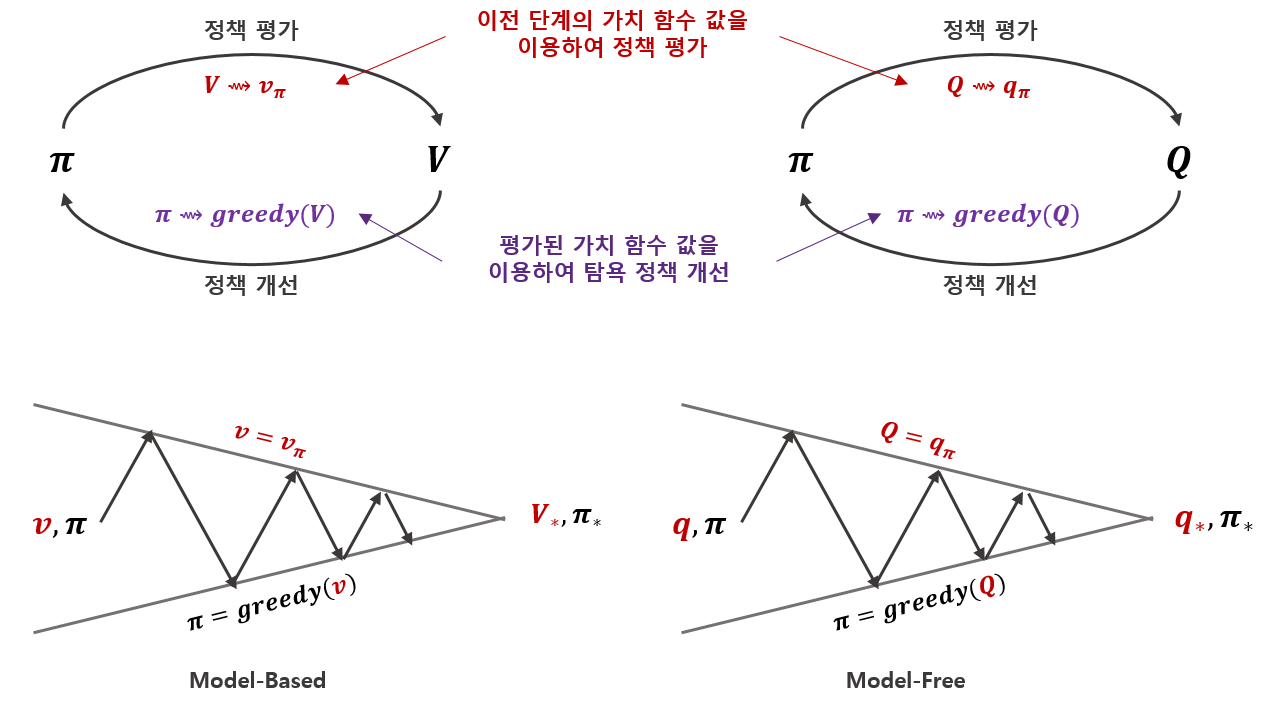
정책 평가는 이전 정책과 현재 정책이 같아야 안정될 것이고, 정책 개선은 현재 가치함수의 탐욕 정책이 이전 정책과 같아야 안정 될 것입니다. 결국 벨만의 최적 방정식을 푸는 것과 같은 의미가 됩니다. 정책 평가와 개선은 동시에 이루어 질 수 없기 때문에 각각을 개선해가며 최적 정책 및 가치함수에 도달해 가는 것입니다.
DP의 문제점
지금까지 DP에 대해 살펴보았고, DP는 이전 포스팅에서 역사적으로 중요한 의미를 갖지만 잘 쓰이진 않는다고 했습니다. 우선 DP는 model을 알고 있는 상태에서 가치함수를 계산하는 것이지 학습하는 것이 아닙니다. 더불어 크게 두 가지 문제가 있습니다.
- 문제점1: 상태공간의 차원이 커지면 모든 내용을 테이블에 관리하며 계산하기 어렵다.
- 문제점2: Model을 아는 경우에만 학습이 가능하다.
위 그리드월드 예제처럼 상태공간이 작은 경우가 거의 없고, model을 아는 경우도 마찬가지입니다. 이런 문제를 해결하기 위해 나온 방법들이 몬테카를로 방법, 시간차학습, 큐러닝등이 있고 앞으로 차차 채워가겠습니다.
마치며
DP에 대해서 살펴보았습니다. 정책 평가, 정책 개선, 정책 반복, 가치 반복의 알고리즘을 살펴보았고, 최적 정책을 찾아가는 원리인 GPI에 대해서 살펴보았습니다. 특히 GPI는 강화학습 전반에 걸쳐서 핵심적인 역할을 합니다. 이상으로 DP 포스팅을 마치고 다음 포스팅에서 찾아뵙겠습니다. :)
References
- Sutton, Richard S., and Andrew G. Barto. Introduction to reinforcement learning. Vol. 2. No. 4. Cambridge: MIT press, 1998.
'Reinforcement Learning > Tabular Methods' 카테고리의 다른 글
| Comparison with Tabular Methods (0) | 2019.12.20 |
|---|---|
| Tabular Temporal Difference Learning - Sarsa, Q-learning, Double Q-learning (0) | 2019.11.11 |
| Monte Carlo Methods in RL (2) (2) | 2019.11.01 |
| Monte Carlo Methods in RL (1) (0) | 2019.10.30 |
| Dynamic Programming In RL (1) (0) | 2019.10.11 |




댓글