Artificial Neural Network (인공신경망)
인공신경망(ANNs; Artificial Neural Networks)은 인간 뇌의 신경망에서 영감을 받은 분석방법으로, 입력($X$)과 반응($Y$)을 모두 알고서 학습하는 지도 학습(Supervised Learning)의 한 부분입니다.

생물학적 뉴런의 수상돌기(Dendrite)은 다른 신경세포로부터 입력(Inputs)을 받아들이는 역할을 합니다. 받아진 입력들은 세포체(Cell body)에서 정해진 방식에 따라 처리를 합니다. 이어서 축색(Axon)은 처리된 정보를 다른 신경세로 전달하는 역할을 합니다.

인공신경망은 생물학적 뉴런의 작동 과정을 흉내낸 것(정확히 같지는 않음)으로, 데이터를 입력(input)으로 받아, 가중치와 입력을 곱한 후 활성함수(Activation function), $f$의 결과를 다음 뉴런으로 보내는 일련의 프레임 워크를 갖습니다.
Components (인공신경망의 구성요소)
인공신경망을 구성하는 요소들을 살펴보겠습니다.
- 노드/유닛 (Node/Unit): 각 층(Layer)를 구성하는 요소.
- 층 (Layer)
- 입력층 (Input Layer): 데이터를 받아들이는 층.
- 은닉층 (Hidden Layer): 데이터를 한 번 이상 처리한 (가중치를 곱하고, 활성함수의 결과를 얻은) 노드로 구성된 층.
- 출력층 (Output Layer): 최종 은닉층 또는 입력층에 가중치를 곱하고, 출력함수의 결과를 얻은 노드로 구성된 층.
- 가중치 (Weight): 노드와 노드간의 연결강도를 나타냄.
- 합 (Summation): 가중치와 노드의 곱을 합하는 것.
- 활성함수 (Activation Function): 합을 처리해 주는 함수로 은닉층 노드의 결과를 얻을 경우 활성함수로 표현.
- 출력함수 (Output Function): 합을 처리해 주는 함수로 출력층 노드의 결과를 얻을 경우 출력함수로 표현.
- 손실함수 (Loss Function): 가중치의 학습을 위해 출력함수의 결과와 반응($Y$)값 간의 오차를 측정하는 함수.

표기법
- $x=h^{(0)}\in\mathbb{R}^{p}$: 입력 벡터.
- $w^{(l)}_{k}$: 가중치 벡터로 $l$ 레이어의 모든 노드에 곱해져, $l+1$ 레이어 $k$ 번째 노드로 연결됨.
- $l\in\{1,...,L\}$, $k\in\{1,...,m_{l}\}$
- $b^{(l)}_{k}$: $l+1$ 레이어 $k$ 번째 노드에 대한 bias.
- $f^{(l)}(\cdot)$: $l$ 은닉층에 대한 활성함수 (Activation Function).
- $h^{(l)}_{k}=f^{(l)}\left(\sum_{j=1}^{m_{l-1}}w_{kj}^{(l-1)}h^{(l-1)}_{j}+b_{k}^{(l-1)}\right)=f^{(l)}\left(w_{k}^{(l-1)\top}h^{(l-1)}+b_{k}^{(l-1)}\right)$: $l$레이어 $k$ 번째 은닉 노드.
- $g(\cdot)$: 출력함수 (Output Function).
- $o_{k}=g\left(w_{k}^{(L)\top}h^{(L)}+b_{k}^{(L)}\right)$: $k$ 번째 출력 노드.
앞으로 수식은 상기 표기법안에서 작성하겠습니다. 인공신경망이 작동하는 과정을 짧게 요약하면 다음과 같습니다.
$$\begin{align*}\text{(Input)} x &\longrightarrow f^{(1)}(w^{(0)\top}x+b^{(0)}) \longrightarrow h^{(1)} \\ h^{(1)} &\longrightarrow f^{(2)}(w^{(1)\top}h^{(1)}+b^{(1)}) \longrightarrow h^{(2)} \\ & \cdots \\ h^{(L)} &\longrightarrow g(w^{(L)\top}h^{(L)}+b^{(L)}) \longrightarrow o \text{(Output)} \end{align*}$$
이어서 데이터를 입력받아 결과를 생성하는 일련의 과정(입력 → 곱 → 활성함수 → 은닉층 → 곱 → 활성함수 → 은닉층 → ...→ 출력)을 자세히 살펴보고 가중치가 어떻게 학습되는지 살펴보도록 하겠습니다.
활성함수 + 출력함수 (Activation Function + Output Function)
활성함수와 출력함수는 가중치와 노드 곱의 합을 활성화 시켜주는 함수입니다. 즉, 생물학적 뉴런의 세포체에서 하는 역할을 수행합니다. 활성함수의 결과는 은닉층 노드 값, 출력함수는 출력층의 노드 값을 내뱉는다는 점에서 약간의 차이가 있습니다.
활성함수 (Activation Function)
활성함수는 노드와 가중치의 곱의 합을 처리해주는 함수로 은닉층의 노드 값을 계산합니다.

이전 포스팅에서 퍼셉트론 모형을 살펴보았는데, 퍼셉트론은 인공신경망에서 활성함수를 step 함수로 적용하되 0대신 thereshold $\theta$를 이용한 특수한 경우로 생각할 수 있습니다. 다시 말해서 퍼셉트론에서 활성함수의 개념이 추가된 것이 인공신경망이라고 할 수 있습니다.

크게 Identity 활성함수 기반, Step 활성함수 기반, Sigmoid 활성함수 기반으로 나누어 생각할 수 있습니다. Identity 기반 함수로는 ReLU 함수가 있고 0보다 작은 $x$에 대하여 0으로 처리한다는 차이가 있습니다. Step 기반 함수는 Sign 함수가 있으며 0보다 작은 구간을 -1로 처리한다는 차이가 있습니다. 마지막으로 Sigmoid 기반 함수는 tanh 함수로 $x\to-\infty$에서 -1로 수렴한다는 차이가 있습니다.
출력함수 (Output Function)
출력함수는 마지막 은닉층의 노드와 가중치의 곱을 처리해주는 함수로 출력층의 노드값을 계산해줍니다. 반응변수 $Y$의 변수타입이 범주형(Categorical), 연속형(Continuous)에 따라 크게 Softmax 함수와 Identity 함수로 구성되며, 각각 분류문제(Classification), 회귀문제(Regression)로 연결됩니다.
- Softmax Function: $$g\left(w^{(L)\top}h^{(L)}+b^{(L)}\right)=\left[\frac{e^{w^{(L)\top}_{1}h^{(L)}+b^{(L)}_{1}}}{\sum_{k=1}^{K}e^{w^{(L)\top}_{k}h^{(L)}+b^{(L)}_{k}}},\dots,\frac{e^{w^{(L)\top}_{K}h^{(L)}+b^{(L)}_{K}}}{\sum_{k=1}^{K}e^{w^{(L)\top}_{k}h^{(L)}+b^{(L)}_{k}}}\right]^{\top}$$
- Identity Function: $$g\left(w^{(L)\top}_{k}h^{(L)}+b^{(L)}_{k}\right)=w^{(L)\top}_{k}h^{(L)}+b^{(L)}_{k}$$
변수 전처리
인공신경망 모형을 적용할 때 변수의 형태(연속형 또는 범주형)에 따라서 간단한 전처리를 해줍니다.
연속형의 경우 가중치 학습시 안정성을 위해 최소-최대 정규화 (Min-max Normalization)을 해줍니다. $$\text{Min-max Normalization: }x=\frac{x-x_{min}}{x_{max}-x_{min}}$$ 최소-최대 정규화를 거치면 처리된 값은 $[0, 1]$ 사이의 값을 갖게됩니다. 여러 연속형 변수가 데이터에 존재할 경우 각 변수의 단위가 다를 수 있습니다. 예를 들어, 키와 몸무게로 성별을 예측하는 모형을 생각할 수 있습니다. 뒤에서 다룰 gradient descent 방법으로 가중치를 학습하는데, 단위가 다를 경우 알고리즘을 불안정하게 만드는 경향이 있다고 알려져 있습니다. 그래서 연속형 변수의 경우 $[0, 1]$ 사이의 값을 갖도록 전처리를 해줍니다.
범주형의 경우 다른 통계 모형처럼 dummy variable 처리를 해주는데, 인공신경망에서는 One-Hot Encoding 방법을 이용합니다. One-Hot Encoding은 범주형 변수의 값을 이진벡터로 맵핑하는 과정입니다. 이어질 예제를 살펴보면 한 번에 이해할 수 있습니다. $$\begin{bmatrix}a\\b\\b\\c\\a\end{bmatrix}\rightarrow\begin{bmatrix}1&0&0\\0&1&0\\0&1&0\\0&0&1\\1&0&0\end{bmatrix}$$ 우측의 칼럼은 순서대로 a, b, c를 나타냅니다.
손실함수 (Loss Function)
손실함수는 딥러닝 프레임에서 생성한 출력 값과 반응변수 $Y$의 차이를 측정하는 함수입니다. 반응변수는 크게 categorical type과 continuous type으로 분류할 수 있습니다. 더 많은 손실함수를 적용할 수 있지만 여기에서는 자주 이용되는 두 가지 손실함수에 대해 다루겠습니다.
- Cross Entropy Loss (Classification): $$l(\theta)=-\sum_{i=1}^{N}\sum_{k=1}^{K}y_{ik}\log{o_{ik}},$$ $y_{ik}$는 실제 라벨 (true label)이고 $o_{ik}$는 딥러닝 프레임워크로부터 계산된 결과 입니다. 분류 문제의 경우 반응변수는 one-hot encoding이 되어 있고, 출력함수로 softmax 함수를 적용합니다. 반응변수의 경우$$y_{i}=\left[0,0,\cdots,1,\cdots,0\right]^{\top}$$의 형태로 $k$번째가 아닌 경우 전부 0입니다. 따라서 cross entropy loss는 $o_{ik}$를 제외하곤 모두 0이 됩니다. 만약 $o_{ik}$가 1에 가깝다면 손실함수는 0에 가까울 것이고, 가중치가 틀려서 0에 가까운 값을 갖는다면 손실함수 값이 커지게 됩니다.
- Mean Square Error Loss (Regression): $$l(\theta)=\sum_{i=1}^{N}\sum_{k=1}^{K}\left(y_{ik}-o_{ik}\right)^{2}$$
예제; 인공신경망 구조
인공신경망을 쉽게 이해하기 위해 익숙한 모형 몇가지를 인공신경망으로 구축해보겠습니다.
예제1 Logistic Regression

$$x\rightarrow g\left(w^{(0)\top}x+b^{(0)}\right)\rightarrow o$$ 로 나타낼 수 있습니다. 여기에서 $g$는 sigmoid 함수이고, 손실함수는 binary-cross entropy loss를 사용합니다. $$o_{1}=\frac{1}{1+e^{-w^{(0)\top}x-b^{(0)}}}, l(\theta)=\sum_{i=1}^{N}y_{i1}\log{o_{1}}.$$
예제2 K-class classification (은닉층 1개)

은닉층이 1개인 $K$-class 분류문제 구조는 위와 같고 $f^{(1)}$ 활성함수는 어떤 것을 이용해도 상관 없고, $g$는 softmax 함수, 손실함수는 cross entropy loss를 적용합니다.
예제3 K-class classification (은닉층 L개)

예제4 Multiple Linear Regression

Logistic regresssion과 동일한 구조에서 $g$를 identity 함수로, 손실함수로 MSE 함수를 사용합니다.
기울기 강하법 (Gradient Descent Algorithms)
인공신경망의 가중치를 학습하기 위해서 기울기 강하법을 사용합니다. 기울기 강하법은 국소 최소값(Local Minimum)을 찾기 위한 수치적인 방법으로 기울기의 역방향으로 값을 조금씩 움직여 함수의 출력 값이 수렴할 때까지 반복하는 것입니다. 기울기 강하법의 자세한 내용은 다음 포스터에서 다루도록하고 여기에서는 개념만 설명하도록 하겠습니다.
어떤 함수 $f$의 국소 최소값을 찾기 위한 기울기 강하법은 $$x^{(k+1)}\leftarrow x^{(k)}-\gamma_{k}\frac{\partial f(x^{(k)})}{\partial x^{(k)}}$$입니다. 여기서 $\gamma_{k}$는 learning rate 혹은 step-size라고 불리우는데 기울기의 역방향으로 $x$를 이동할 크기를 조정하는 역할을 합니다.
기울기 강하법에서 주의해야 할 두가지가 있습니다. 첫 번째는 초기값 $x^{(0)}$이며, 두 번째는 learning rate $\gamma_{k}$입니다. 만약 learning rate가 적절하지 못하면 다음의 문제가 발생합니다.
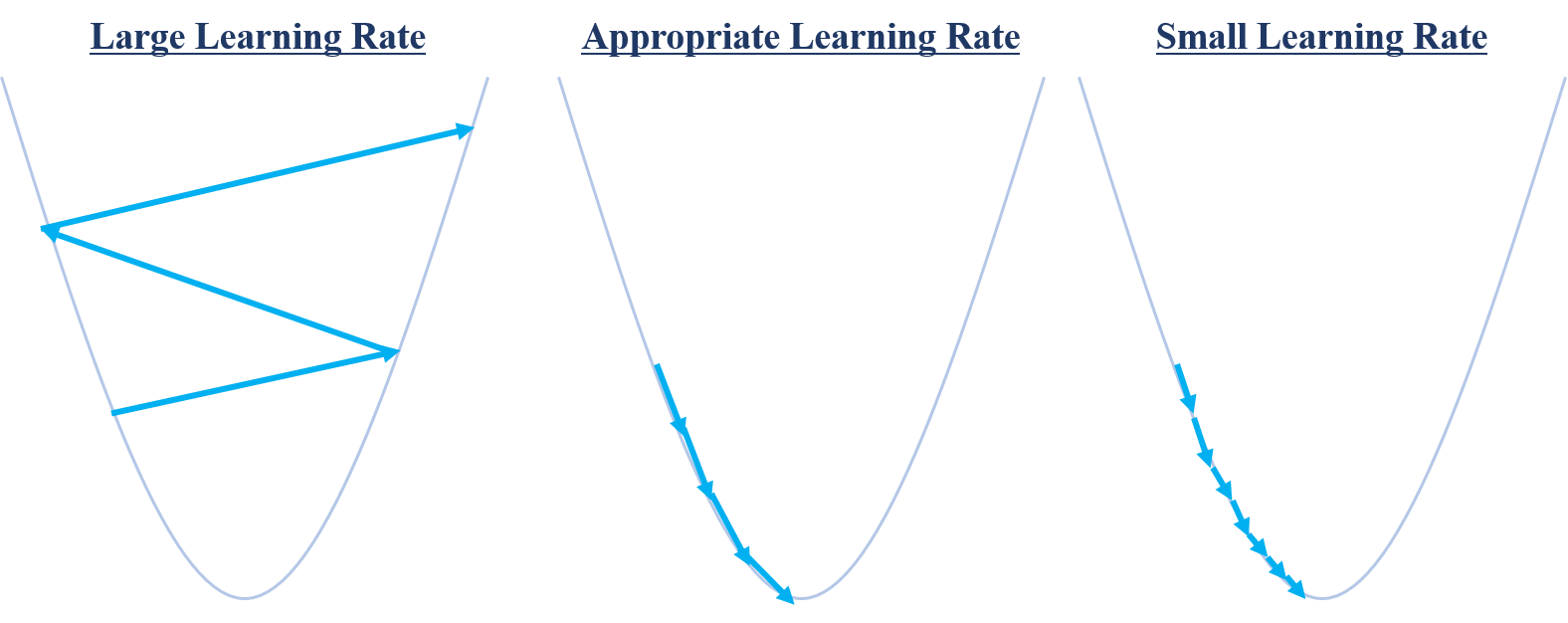
최소값을 찾기 위해 움직이는데 학습률이 너무 크면 오히려 알고리즘이 수렴하지 않고 발산해버릴 수도 있습니다. 만약 값이 너무 작다면 수렴까지 오랜시간이 걸리게 됩니다. 가운데 상황처럼 적당한 학습률을 정해줄 필요가 있습니다. 만약 함수가 울퉁불퉁하다면 즉 convex또는 concave 함수가 아니라면 초기값에 따라 국소 최소값이 달라지게 됩니다.

Figure 11처럼 같은 learning rate를 이용했을 경우 어디서 출발하느냐에 따라서 국소 최소값의 결과가 달라질 수 있습니다. 물론 Gradient Descent 방법 자체가 국소 최소값을 찾는 알고리즘이지만, 인공신경망의 목표는 손실함수의 최소값 (Global Minimum)을 찾는 것이기 때문에 initial value 1에서 시작하는 것이 바람직합니다. 이어서 인공신경망에서 기울기 강하법이 어떻게 적용되는지 살펴보겠습니다.
역전파 (Backpropagation)
역전파 (Backpropagation) 알고리즘은 손실함수로부터 측정된 오차를 출력층부터 입력층까지 역전파하여 연쇄적으로 가중치를 학습하는 방법입니다. 역전파 알고리즘은 다음의 순서로 진행됩니다.
- 주어진 가중치를 이용해 입력값을 (앞)전파시킨다.
- 출력층에 도달했을때 손실함수를 이용하여 오차를 측정한다.
- 오차에 대한 정보를 부모층으로 역전파한다.
- 모든 가중치의 gradients를 계산한다.
- Gradient Descent 방법을 이용하여 가중치를 update한다.
- 수렴할 때까지 1~5를 반복한다.

사실 제 경우에는 예제를 보기전까진 역전파라는 컨셉이 잘 와닿지 않았습니다. 그래서 이어서 예제를 한 번 살펴보겠습니다.
예제1. MSE Loss

활성함수 ReLU, 출력함수 Identity, 손실함수를 MSE Loss로하는 위와 같은 구조의 인공신경망을 고려하겠습니다. 그러면 $w_{11}^{(2)}$의 gradient는 $$\frac{\partial l}{\partial w_{11}^{(2)}}=\frac{\partial l}{\partial o_{1}}\frac{\partial o_{1}}{\partial w_{11}^{(2)}}=-2(y_{11}-o_{1})h_{1}$$으로 계산할 수 있습니다. 이어서 $w_{11}^{(1)}$의 gradient는 $$\begin{align*}\frac{\partial l}{\partial w_{11}^{(1)}}&=\frac{\partial l}{\partial o_{1}}\frac{\partial o_{1}}{\partial h_{1}}\frac{\partial h_{1}}{\partial w_{11}^{(1)}}+\frac{\partial l}{\partial o_{2}}\frac{\partial o_{2}}{\partial h_{1}}\frac{\partial h_{1}}{\partial w_{11}^{(1)}}\\&=-2(y_{11}-o_{1})w_{11}^{(2)}x_{1}-2(y_{1w}-o_{w})w_{11}^{(2)}x_{1}\end{align*}$$가 됩니다.

$w_{11}^{(1)}$은 $h_{1}$에 영향을 주었고, $h_{1}$은 $o_{1}$과 $o_{2}$에 영향을 주었습니다. 따라서 $w_{11}^{(1)}$의 gradient를 계산하기 위해선 뒷단의 $w_{11}^{(2)}$, $w_{12}^{(2)}$의 오차 정보가 반영되어야 됩니다. 위 그림이 이러한 관계를 표시한 것인데 거꾸로 전파되는 형상이어서 역전파 알고리즘으로 불립니다. 모든 가중치에 대한 gradients가 계산되고 나면, $$w_{ij}^{(l)}\leftarrow w_{ij}^{(l)}-\eta\frac{\partial l}{\partial w_{ij}^{(l)}}$$ gradient descent 방법으로 가중치를 업데이트하고, 이를 수렴할 때 까지 반복합니다.
예제2. Cross Entropy Loss
같은 구조에서 활성함수가 ReLU, 출력함수가 Softmax, 손실함수가 Cross Entropy인 경우의 역전파 알고리즘을 살펴보겠습니다. 출력층의 노드의 값은 $$o_{k}=\frac{e^{z_{k}}}{\sum_{k=1}^{K}e^{z_{k}}}$$이고, 여기에서 $z_{k}=w_{1k}^{(2)}h_{1}+w_{2k}^{(2)}h_{2}$가 되겠습니다. $w_{11}^{(2)}$의 기울기는 $$\frac{\partial l}{\partial w_{11}^{(2)}}=\frac{\partial l}{\partial o_{1}}\frac{\partial o_{1}}{\partial z_{1}}\frac{\partial z_{1}}{\partial w_{11}^{(2)}}+\frac{\partial l}{\partial o_{2}}\frac{\partial o_{2}}{\partial z_{1}}\frac{\partial z_{1}}{\partial w_{11}^{(2)}}=(o_{1}-y_{11})h_{1}$$이고, 여기에서 $$\begin{align*}\frac{\partial o_{1}}{\partial z_{1}}&=\frac{e^{z_{1}}}{\sum_{k=1}^{K}e^{z_{k}}}-\left(\frac{e^{z_{1}}}{\sum_{k=1}^{K}e^{z_{k}}}\right)^{2}=o_{1}(1-o_{1})\\ \frac{\partial o_{2}}{\partial z_{1}}&=-\frac{e^{z_{1}}e^{z_{2}}}{\left(\sum_{k=1}^{K}e^{z_{k}}\right)^{2}}=-o_{1}o_{2}\end{align*}$$입니다. 같은 방식으로 $w_{11}^{(1)}$의 기울기를 구해보면, $$\begin{align*} \frac{\partial l}{\partial w_{11}^{(1)}}=&\frac{\partial l}{\partial o_{1}}\frac{\partial o_{1}}{\partial z_{1}}\frac{\partial z_{1}}{\partial h_{1}}\frac{\partial h_{1}}{\partial w_{11}^{(1)}}+\frac{\partial l}{\partial o_{2}}\frac{\partial o_{2}}{\partial z_{1}}\frac{\partial z_{1}}{\partial h_{1}}\frac{\partial h_{1}}{\partial w_{11}^{(1)}}\\&+\frac{\partial l}{\partial o_{1}}\frac{\partial o_{1}}{\partial z_{2}}\frac{\partial z_{2}}{\partial h_{1}}\frac{\partial h_{1}}{\partial w_{11}^{(1)}}+\frac{\partial l}{\partial o_{2}}\frac{\partial o_{2}}{\partial z_{2}}\frac{\partial z_{2}}{\partial h_{1}}\frac{\partial h_{1}}{\partial w_{11}^{(1)}}\\=&(o_{1}-y_{11})w_{11}^{(2)}x_{1}+(o_{2}-y_{12})w_{12}^{(2)}x_{1}.\end{align*}$$ 마찬가지로 모든 가중치에 대한 gradients가 계산되고 나면, $$w_{ij}^{(l)}\leftarrow w_{ij}^{(l)}-\eta\frac{\partial l}{\partial w_{ij}^{(l)}}$$ gradient descent 방법으로 가중치를 업데이트하고, 이를 수렴할 때 까지 반복합니다.
기울기 소실문제 (Vanishing Gradients Problem)
기울기 소실문제란 인공신경망의 상단 가중치의 기울기를 계산할 때, 하단의 기울기가 0에 가까운 것이 많아서 기울기가 0으로 계산되고 학습이 안되는 문제를 말합니다. 역시 간단한 예제를 통해서 진행하도록 하겠습니다.

$f^{(l)}$, $g$ 모두 sigmoid 함수를 이용하고, 각층의 노드가 1개이고 은닉층이 3개인 아주 간단한 형태의 인공신경망을 생각해보겠습니다. 다음을 확인할 수 있습니다. $$\begin{align*} \frac{\partial l}{\partial w_{1}^{(4)}}&=\frac{\partial l}{\partial o_{1}}\frac{\partial o_{1}}{\partial w_{1}^{(4)}}=\frac{\partial l}{\partial o_{1}}\sigma'(w_{1}^{(4)}h^{(3)}_{1})h_{1}^{(3)}\\ \frac{\partial l}{\partial w_{1}^{(3)}}&=\frac{\partial l}{\partial o_{1}}\frac{\partial o_{1}}{\partial h_{1}^{(3)}}\frac{\partial h_{1}^{(3)}}{\partial w_{1}^{(3)}}=\frac{\partial l}{\partial o_{1}}\sigma'(w_{1}^{(4)}h^{(3)}_{1})w_{1}^{(4)}\sigma'(w_{1}^{(3)}h_{1}^{(2)})h_{1}^{(2)}. \end{align*}$$ (4)에서 (1)로 갈수록, 즉, 상단의 가중치로 갈수록 sigmoid 1차 미분값이 계속해서 곱해지는 것을 확인할 수 있고, 결국 0으로 수렴할 것입니다. 이렇게 되면 하단의 가중치는 학습이 되겠지만, 상단의 가중치는 전혀 학습이 안됩니다. 이러한 문제를 기울기 소실문제라고 합니다.
Universal Approximation Theorem

1989년 G. Cybenko가 발표한 논문으로 sigmoid 함수를 활성함수로 이용하면 1개의 은닉층에 충분한 노드가 갖추어지면, 즉, 충분히 노드의 수가 많으면, 여러개의 은닉층으로 구성된 함수로 근사시킬 수 있다는 이론입니다. 자세한 증명은 Cybenko의 논문에서 확인할 수 있습니다.
정리하며
인공신경망은 기울기 소실문제와 universal approximation theorem이 발표된 이후 제 2의 빙하기에 접어들게됩니다. 위에서 ReLU 활성함수를 미리 소개했지만, 기울기 소실문제를 극복하기 위한 노력의 일환이고, 같은 맥락에서 발전된 형태의 Gradient Descent 방법이 등장하며 인공신경망이 살아나기 시작합니다. 이때 부터 인공신경망은 Deep Learning으로 다시 불리우게 됩니다.
References
- Wikipedia contributors. "Artificial neural network." Wikipedia, The Free Encyclopedia. Wikipedia, The Free Encyclopedia, 29 May. 2019. Web. 29 May. 2019.
- Cybenko, George. "Approximations by superpositions of a sigmoidal function." Mathematics of Control, Signals and Systems 2 (1989): 183-192.
'Deep Learning > Neural Network' 카테고리의 다른 글
| Perceptron (Deep Learning의 시작) (0) | 2019.05.24 |
|---|

댓글