직전 포스팅에서 MAB 개요 중, MAB, Exploration-Exploiation Trade-off, Application Example등을 살펴보았습니다. 이번 포스팅에서는 본격적으로 MAB Algorithm을 다루기 앞서 (1) 제 블로그를 읽어가기 위한 notation에 대한 framework을 제시하고, (2) 앞으로 다루게될 MAB Algorithm와 대응하는 branches를 제시해보고자 합니다.
Glossaries and Notation of MAB
앞으로 다룰 MAB 문제를 풀기위한 알고리즘 설명을 위한 용어와 수식 notation을 정리해보겠습니다.
행동의 주체를 Bandit, Player, Agent라고 합니다. 이 Player는 매 라운드별 행동을 선택합니다. 이때 라운드는 round, time-step 등으로 표현되고, 매 라운드의 선택가능 한 행동을 arm, action으로 표현합니다. 라운드를 시작하기전 관측가능한 정보가 있습니다. 예를 들어, 어떤 라운드 $t$에서 웹사이트에 게시할 뉴스를 선택해야되는데, 행동의 주체가 20대, 여성이라는 정보를 알 수 있는 경우가 있습니다. 이러한 사전의 정보를 context라고 합니다.
위 내용을 요약하면, 어떤 행동의 주체에 대하여 행동 선택 전, 관측가능한 정보를 고려해여, 어떤 라운드 $t$에서 최적의 arm $a$를 선택한 상황입니다. 이렇게 어떤 행동을 선택하고 나면, 보상이 얻어집니다. 이 보상을 reward, pay-off등으로 표현합니다.
- time-step, round: $t\in\{1,\cdots,T\}$
- arms, actions at round $t$: $a_{t}\in\{1,\cdots,K\}=\mathcal{A}$
- context at round $t$: $x_{t}$
- reward, pay-off: $r_{1},\cdots,r_{T}$
MAB를 푼다는 것은 매라운드에서 최적의 보상을 얻을 수 있는 의사결정 함수($t\rightarrow \mathcal{A}$)를 얻는 것과 같습니다. MAB에서는 문제를 풀기위한 목적 함수를 regret이라고 합니다. 큰 틀에서 regret는 최적 의사결정 보상과 알고리즘 의사결정 보상의 차이로 정의됩니다. 다만 regret은 앞으로 다룰 stochastic bandit, bayesian bandit, contextual bandit, adversarial bandit등 문제를 해결하는 방식에 따라 정의하는 방식의 차이가 있습니다. 우선은 아주 rough하게 정의하겠습니다. $$Regret=\underset{a}{\operatorname{max}}\sum_{t=1}^{T}r_{t, a}-\sum_{t=1}^{T}r_{t,ALG(t)}$$ 눈치 채셨겠지만, 결국 가장 중요한건 Reward이고 reward을 어떻게 해석하고, 다루는 방법에 따라서 수많은 bandit 알고리즘이 존재하게 됩니다.
Branches of MAB
앞서 말씀드린것 처럼 reward를 해석하는 방법은 MAB 알고리즘을 이해하는데 key point가 됩니다. 제 나름대로 MAB를 분류해둔 것으로 아래내용이 모든 Algorithm을 커버하진 않지만, 핵심은 모두 담고자 노력했습니다.
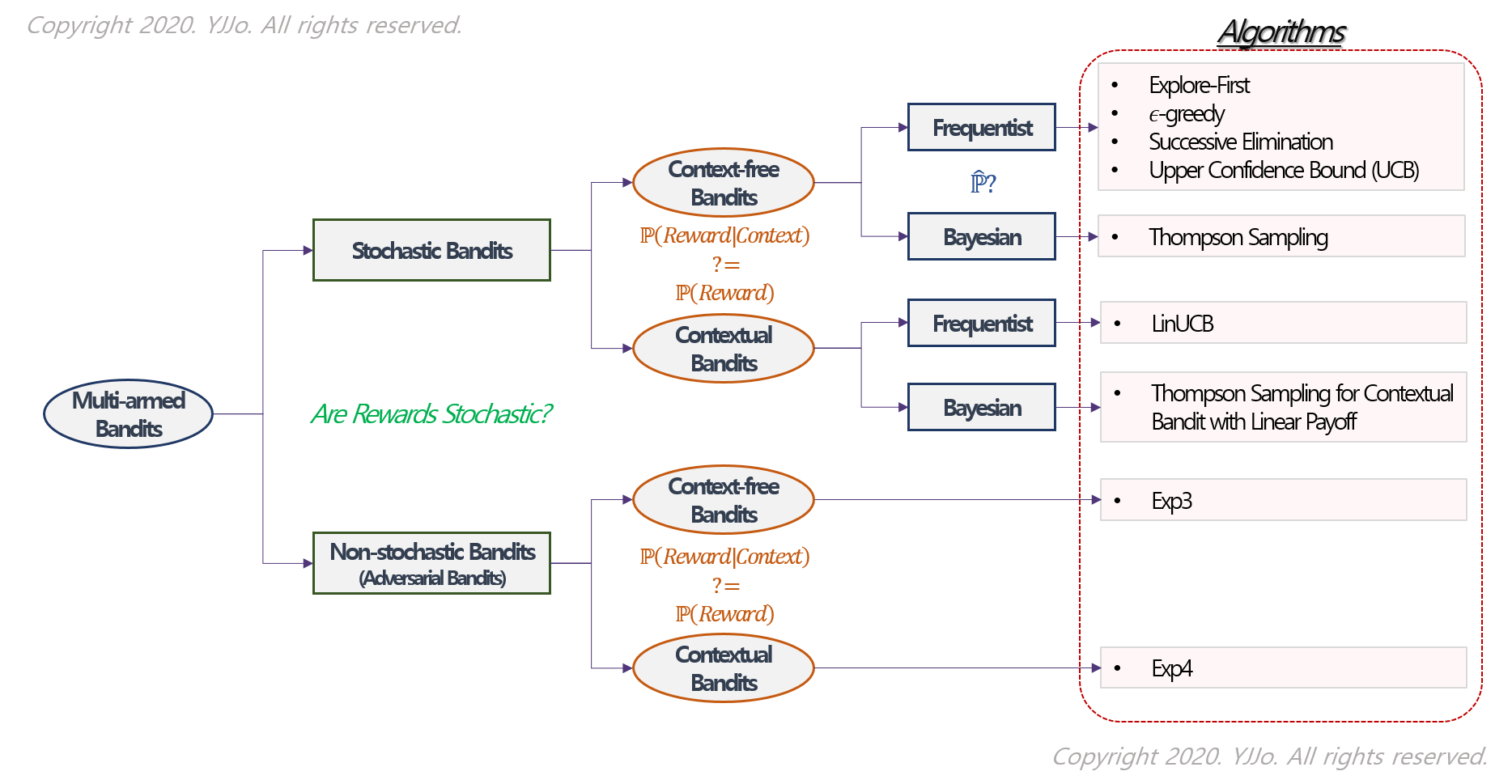
가장 큰 분류는 Reward의 Stochastic 여부로 나누는 것 입니다. 만약에 어떤 확률 분포를 가정할 수 있다면, reward의 확률 분포를 추정하는 방식이 MAB를 푼다고 볼 수 있습니다. 그 다음 위 용어 정리에서 말씀드린 것처럼 context의 유무입니다. 위에선 context가 항상 있는 것처럼 말씀드렸지만, 상황에 따라서 context가 있을 수도, 없을 수 도 있기 때문에 상황에 맞는 풀이법으로 이어지게 됩니다. 마지막으론 Frequentist, Bayesian 두 관점에서의 추정입니다. Non-stochastic은 확률분포를 가정하지 않기 때문에 해당사항이 없습니다. Stochastic인 경우 통계학의 추정에 양대산맥인 빈도론자 관점, 베이지안 관점에서 다른 추정법을 적용할 수 있습니다.
Summary
이상으로 MAB의 Introduction을 마치도록 하겠습니다. Branches부분은 정말 긴시간을 갖고 만들어 낸거라 얼마든지 사용하셔도 좋지만 꼭 출처를 밝혀주셨으면 좋겠습니다. :)
위 포스팅에 앞으로 진행사항에 대한 힌트가 많이 언급되어 있습니다. (1) MAB를 푸는 방법엔 수많은 논문이 있지만, 제 기준에서 핵심이 되는 알고리즘인 Branches of MAB 우측 끝에 등장한 알고리즘에 대해서만 다루려고 합니다. (2) Regret이 목적함수라고 했지만, MAB 특성상 실제 문제에서 최적의 선택을 쉽게 알 수 없기 때문에 딥러닝, 머신러닝처럼 수치적인 해결방법보다는, 어떤 알고리즘을 제시하고 해석적인 Regret을 얻는 과정으로 진행이 됩니다.
다만... 제가 수학을 잘하진 않아서.. (2)에 대해선 정말 간략한 수준으로만 언급하고 최대한 내용을 전달하는데 힘을 주려고 합니다.
긴글 읽어주셔서 감사합니다:)
yjjo.tistory@gmail.com
References
Slivkins, Aleksandrs. "Introduction to multi-armed bandits."arXiv preprint arXiv:1904.07272(2019).
Wikipedia contributors. "Multi-armed bandit." Wikipedia, The Free Encyclopedia. Wikipedia, The Free Encyclopedia, 22 Oct. 2020. Web. 30 Nov. 2020.
Li, Lihong, et al. "A contextual-bandit approach to personalized news article recommendation." Proceedings of the 19th international conference on World wide web. 2010.
Agrawal, Shipra, and Navin Goyal. "Thompson sampling for contextual bandits with linear payoffs." International Conference on Machine Learning. 2013.
'Reinforcement Learning > Multi-Armed Bandits' 카테고리의 다른 글
| Stochastic Bandits (3) - UCB (Upper Confidence Bound) (0) | 2021.01.03 |
|---|---|
| Stochastic Bandits (2) - ε-greedy (0) | 2020.12.18 |
| Stochastic Bandits (1) - Introduction (0) | 2020.12.09 |
| Introduction to Multi-Armed Bandits (1) (2) | 2020.12.01 |
| Multi-Armed Bandits (0) | 2020.11.26 |


댓글